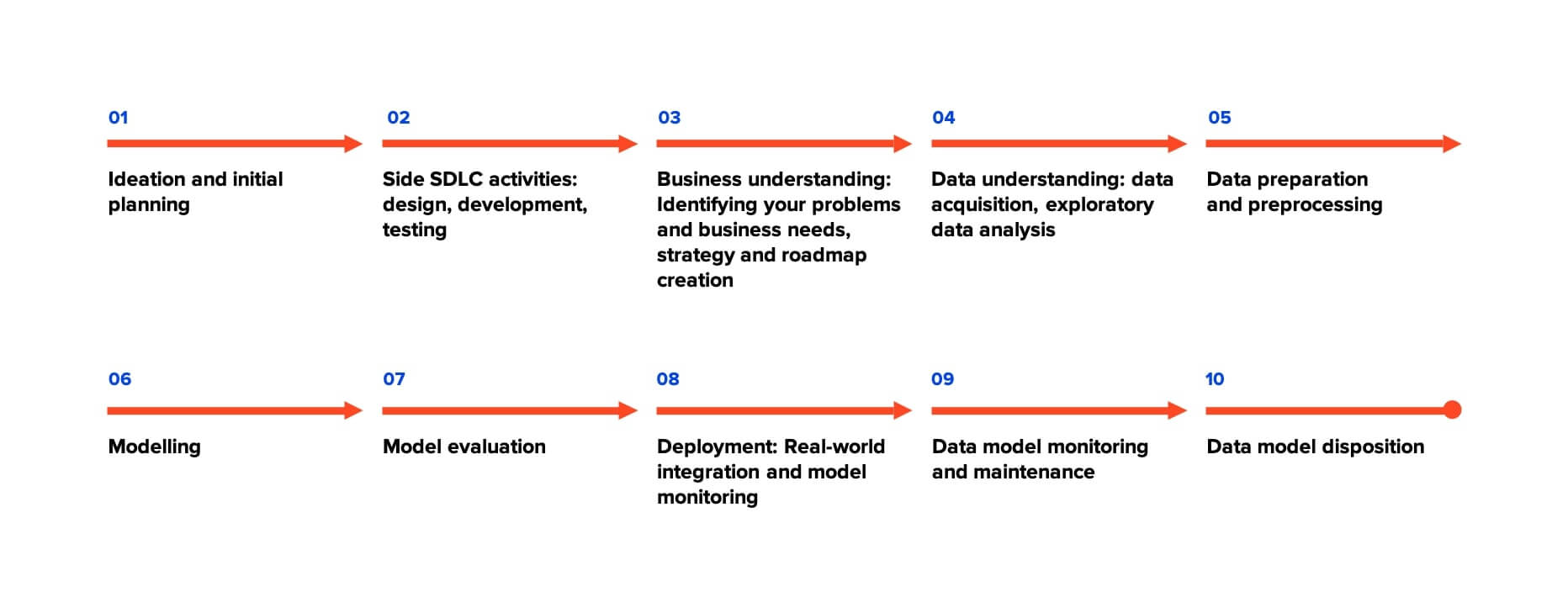
1. Ideation and initial planning
Without a valid idea and a comprehensive plan in place, it is difficult to align your model with your business needs and project goals to judge all of its strengths, its scope and the challenges involved. First, you need to understand what business problems and requirements you have and how they can be addressed with a data science solution.
At this stage, we often recommend that businesses run a feasibility study – exhaustive research that allows you to define your goals for a solution and then build the team best equipped to deliver it. There are usually several other software development life cycle (SDLC) steps that will run in parallel with data modelling, including solution design, software development, testing, DevOps activities and more. The planning stage is to ensure you have all required roles and skills in your team to make the project run smoothly through all of its stages, meet its purpose and achieve its desired progress within the given time limit.
2. Side SDLC activities: design, software development and testing
As you kick off your data analysis and modelling project, several other activities usually run in parallel as parts of the SDLC. These include product design, software development, quality assurance activities and more. Here, team collaboration and alignment are key to project success.
For your model to be deployed as a ready-to-use solution, you need to make sure that your team is aligned through all the software development stages. It's essential for your data scientists to work closely with other development team members, especially with product designers and DevOps, to ensure your solution has an easy-to-use interface and that all of the features and functionality your data model provides are integrated there in the way that’s most convenient to the user. Your DevOps engineers will also play an important role in deciding how the model will be integrated within your real production environment, as it can be deployed as a microservice, which facilitates scaling, versioning and security.
When the product is subject to quality assurance activities, the model gets tested within the team's staging environment and by the customer.
3. Business understanding: Identifying your problems and business needs, strategy and roadmap creation
The importance of understanding your business needs, and the availability and nature of data, can’t be underestimated. Every data science project should be ‘business first’, hence defining business problems and objectives from the outset.
And in the initial phase of a data science project, companies should also set the key performance indicators and criteria that will be indicative of project success. After defining your business objectives, you should assess the data you have at your disposal and what industry/market data is available and how usable it is.
- Situational analysis. Experienced data scientists should be able to assess your current operational performance, then define any challenges, bottlenecks, priorities and opportunities.
- Defining your ultimate goals. Undertake a rigorous analysis of how your business goals match the modelling approach and understand where the gaps in performance and technology are, to define the next steps.
- Building your data modelling strategy. When defining your strategy, two aspects are essential – your assets available and how well the potential strategy answers your business goals – before building business cases to kick start the process.
- Creating a roadmap. After you have a strategy in place, you need to design a roadmap that encompasses programs that will help you reach your goals, what the key objectives are within each program and all necessary project milestones.
The most important task within the business understanding stage is to define whether the problem can be solved by the available or state-of-the-art modelling and analysis approaches. The second most important task is to understand the domain, which allows data scientists to define new model features, initiate model transformations and come up with improvement recommendations.
4. Data understanding: data acquisition and exploratory data analysis
The preceding stages were intended to help you define your criteria for data science project success. Having those available, your data science team will be able to prepare your data for analysis and recommend which data to use and how.
The better the data you use, the better your model is. So, an initial analysis of data should provide some guiding insights that will help set the tone for modelling and further analysis. Based on your business needs, your data scientists should understand how much data you need to build and train the model.
How can you tell good data from bad data? Data quality is imperative, but how are you to know if your information really isn’t up to the required standard? Here are some of the ‘red flags’ to watch out for:
- It has missing variables and cannot be normalised to a unique basis.
- The data has been collected from lots of very different sources. Information from third parties may come under this banner.
- The data is not relevant to the subject of the algorithm. It might be useful, but not in this instance.
- The data contains contradicting values. This could see the same values for opposing classes or a very broad variation inside one class.
- Upon meeting any one of these red flags, there’s a chance that your data will need to be cleaned prior to your implementation of an ML algorithm.
Types of data that can be analysed include financial statements, customer and market demand data, supply chain and manufacturing data, text corpora video and audio, image datasets, as well as time series, logs and signals.
Some types of data are a lot more costly and time-consuming to collect and label properly than others; the process can take even longer than the modelling itself. So, you need to understand how much cost is involved, how much effort is needed and what outcome you can expect, as well as your potential ROI, before you make a hefty investment in the project.
5. Data preparation and preprocessing
Once you’ve established your goals, gained a clear understanding of the data needed and acquired the data, you can move on to data preprocessing. The best method for this depends on the nature of the data you have: there are, for example, different time and cost ramifications for text and image data.
It’s a pivotal stage, and your data scientists need to tread carefully when they’re assessing data quality. If there are data values missing and your data scientists use a statistical approach to fill in the gaps, it could ultimately compromise the quality of your modelling results. Your data scientists should be able to evaluate data completeness and accuracy, spot noisy data and ask the right questions to fill any gaps, but it's essential to engage domain experts, for consultancy.
Data acquisition is usually done through an Extract, Transform and Load (ETL) pipeline.