Recommender systems research has incorporated a wide variety of artificial intelligence techniques including machine learning, data mining, user modeling, case-based reasoning and constraint satisfaction to name a few. This article will take stock of the current landscape of recommender systems research and identify directions the field is now taking.
What Recommender Systems are and What They Do
Abstractly speaking, recommender systems (RS) are techniques that provide suggestions for any type of content to be of use to a user being closely related to a decision-making processes. In their simplest form personalized recommendations are offered as ranked lists of items. In performing this ranking, RSs try to predict the most suitable products or services based on the user’s preferences and constraints.
Briefly, all of RSs are based on the following informational components: information about user, information about items and information about transactions (or any similar action). To implement its core function - identifying items useful for the user - a RS must predict that an item is worth recommending. For this, the system has to be able to predict the utility of some of them, or at least compare the utility of some items and decide what items to recommend based on this comparison.
The purposes to use RS may be different:
- Assistance in decision making
- Assistance in comparison
- Assistance in discovery
- Assistance in exploration
RS can also be used to calculate several behavioral aspects of the following user portraits:
- Non-loyal users and popular items
- Non-loyal users and unpopular items
- Loyal users and popular items
- Loyal users and unpopular items
RS can be treated as one of the most efficient tools for business, aimed directly at increasing revenue and profitability as well as optimizing current product portfolio. The following industries showed a rapid demand-led growth for implementing RS solutions:
- Retail business: market basket analysis, sequential patterns mining, user profiling, goods portfolio optimization
- Hotel business and tourism: tour and hotel recommendations based on ratings and user preferences
- Digital content: recommendation of new items based on purchases or visits history
- Movie databases: recommendations based on user’s rating
Let me demonstrate the basics of core recommendation computation as a prediction of utility of an item for a user. Let’s model the utility degree of a user U for an item A as a function R (U, A), as is normally done by considering user ratings for items. The fundamental task of collaborative filtering RS is to predict the value of R over pairs of users and items, i.e., to compute Re (U, A) where Re is estimation, calculated by the RS, of the true function R. Therefore, after computing this prediction for the active user U on a set of items, i.e., Re (U, A1), . . . , Re(U, An) the system will recommend items (A j1 , . . . , A jK (K ≤ N) with the largest predicted utility. K is typically a small number, much smaller than the cardinality of the item data set or the items on which a user likeness prediction can be computed, i.e., RSs “filter” the items that are recommended to users.
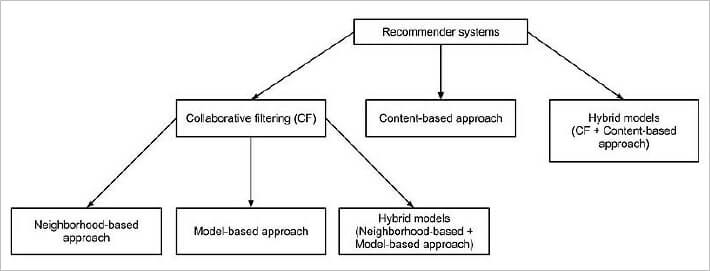
Types of Recommender Systems
Typically, recommender systems are classified according to the technique used to create a recommendation: