
Background & experience:
- Over 15 years of practical experience in advanced data analysis and modelling. Currently manages a large AI team while providing presales and delivery support for complex AI implementations.
- Technical expertise encompasses the full spectrum of AI technologies: NLP/AI agents for document/information processing and assistance, compliance checks, computer vision for security and monitoring systems, AI-based RPA for process automation, and predictive modelling for policy planning and resource optimisation.
Do you agree with the thesis that data quality is more important than model quality?
Volodymyr Getmanskyi: It depends on the task, chosen approach and known limitations. For example, sometimes there is no sufficient data available, and it is impossible to gather data, so an AI specialist should find additional approach besides classical machine learning (model training).
Modern generalised and foundation models, especially multimodal LLMs, can be used as a magic wand here, just as some types of knowledge sharing and model inferencing. For such cases, data volumes and quality are not so critical, because it will be extended by the pretrained model or LLM possibilities (at least in terms of semantic and lexical understanding).
For other cases, where the need is new, the domain is specific, internal knowledge is more important, data gathering and processing are among the main steps and can't be underestimated against the model quality. But please take into account that the final and whole approach (or future model training) can also influence the data requirements.
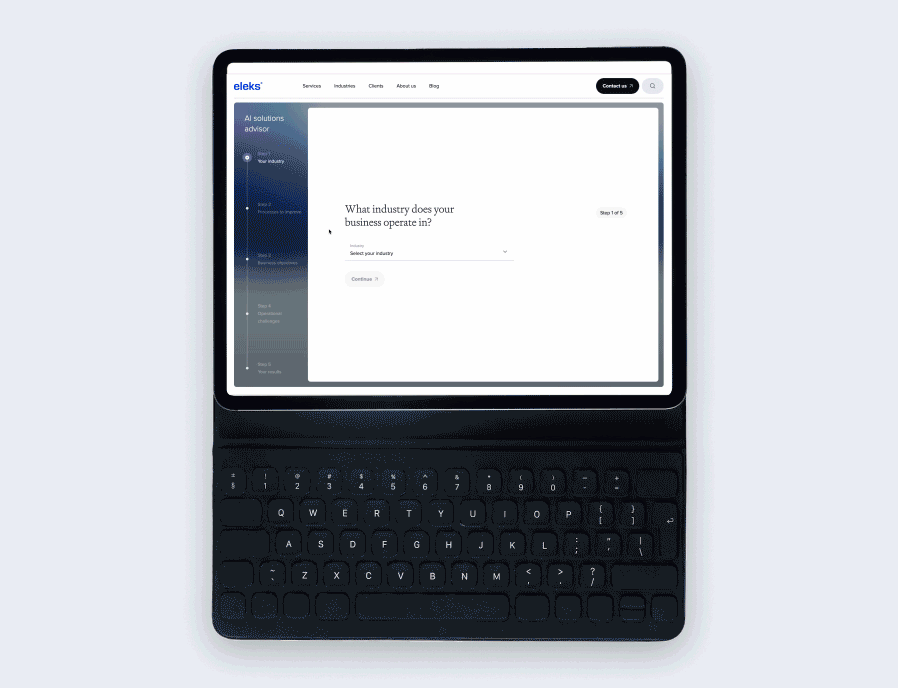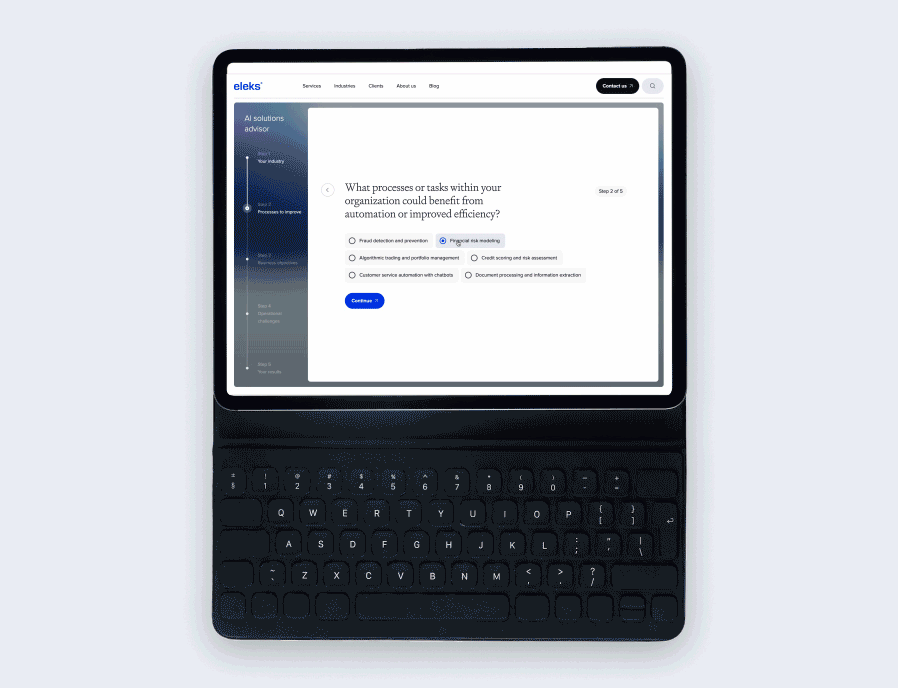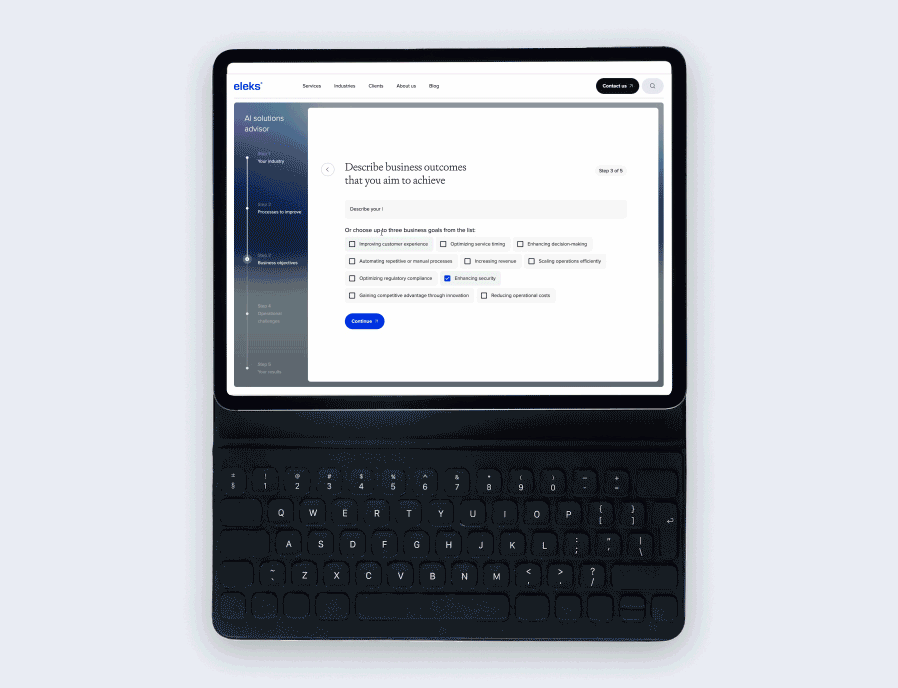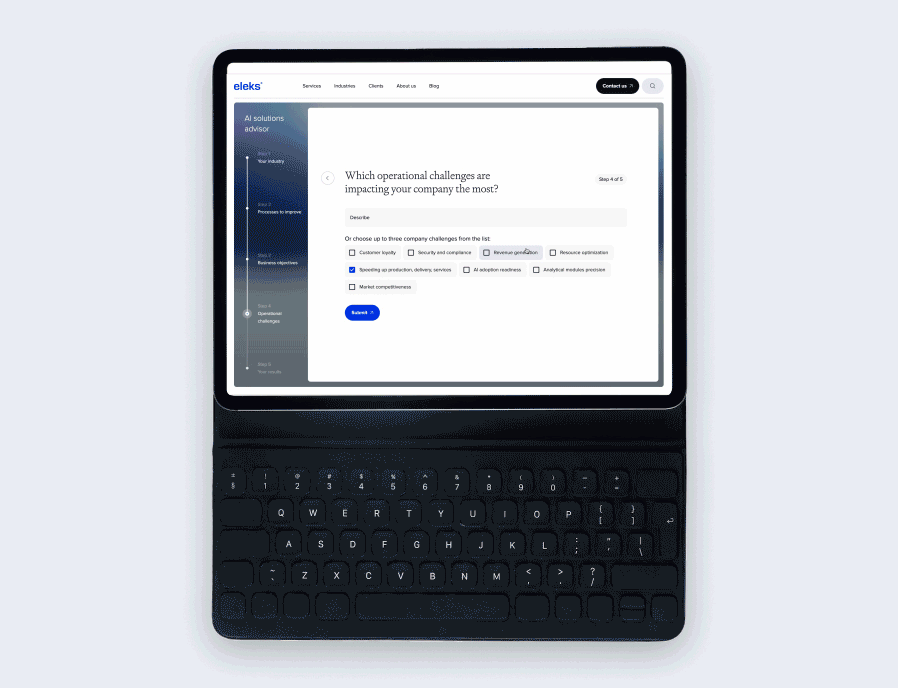
Which data cleaning and augmentation techniques are most effective in your practice?
VG: It depends on the data type and need. For example, augmentation is not always used because there should be some specific circumstances, like a small number of samples or an imbalanced or unrepresentative dataset (future samples might be different from those that were gathered, so we need to generalise more or increase the robustness). That’s why it is not about efficiency, but about need, approach, and limitations.
Regarding data cleansing and preprocessing, this is a must-have step for any analytics and modelling task, where we prepare data for further modelling and provide the stakeholders with descriptive analysis and insights (or recommendations) about it.
How to organise processes in the team to have data quality in focus?
VG: First, the meaning of data quality and associated metrics should be defined. They should be evaluated during the whole AI development cycle. The reassessments should be done after any processing approach changes, new data batches/imputation, or model redesign (sometimes different models require different data preparation approaches).
Then, in case we are changing the approach or data rapidly, there should be a data versioning process, where you monitor changes and can return to a previous version.
Finally, the data check and audit process should have an owner in RACI, define a responsible specialist (data engineer, data scientist or AI engineer), to be sure that these activities are always in scope and focus.
So, probably these are the first basic steps for a data-focused development organisation.

What are the biggest challenges you have encountered in the data-centric approach?
VG: There are many of them, but I want to mention three, the most important ones, besides initial data gathering and further processing.
The first one is the signal-vs-noise philosophy. To simplify, the data consists of signal and noise, where the signal is something useful for us (for AI purposes or solutions). Meanwhile, the noise is a mixed component with real noise, errors, missing information, but also with the unexplained dependencies/fluctuations, unnecessary information or overload.
The biggest challenge here is to understand what the signal is and how to distinguish it from noise for further noise removal/filtering. For instance, imagine the task of automating some processes or a specialist’s whole day activities, where, besides the straightforward goal following, there may be different interruptions, side activities, communication, 5-minute breaks, etc. And the question is – what is important and should be automated (the signal), considering that processes can be very similar (project communication vs. side communication)?
The second challenge is contradictory samples, which can be in two forms:
- similar independent variables (features) and too different dependent variables (targets/labels),
- different features, but a similar target.
For example, let’s imagine some educational process, where we know students’ efforts and the final evaluation. So, the first type of contradiction appears when there are students who spent the same time, got similar feedback, etc., but the final evaluation/exam result is opposite. In this situation, the further model loss will be jumping from one extreme to another, and finally, the model won’t be confident in such cases and inputs.
The second type occurs when there may be two students who got an A+ as their final exam result, but their efforts are completely different. The first one has positive feedback and great transitional assessment grades, while the second one has negative feedback, low grades, etc. Probably, there was some fraud involved in the final evaluation or during the study, but we don’t know, and this is the contradictory samples. In this situation, the factor analysis may become impossible – “what actions should we take to have a successful exam result”.
The final one, which I want to highlight, is the data and concept drift. This is the situation when the input data features, internal dependencies or nature of the target have changed, especially after several model/approach improvement iterations. In this case, there will also be a drift in model performance, with less precise results. This is one of the known tasks for monitoring, which I mentioned above.


Related insights








The breadth of knowledge and understanding that ELEKS has within its walls allows us to leverage that expertise to make superior deliverables for our customers. When you work with ELEKS, you are working with the top 1% of the aptitude and engineering excellence of the whole country.

Right from the start, we really liked ELEKS’ commitment and engagement. They came to us with their best people to try to understand our context, our business idea, and developed the first prototype with us. They were very professional and very customer oriented. I think, without ELEKS it probably would not have been possible to have such a successful product in such a short period of time.

ELEKS has been involved in the development of a number of our consumer-facing websites and mobile applications that allow our customers to easily track their shipments, get the information they need as well as stay in touch with us. We’ve appreciated the level of ELEKS’ expertise, responsiveness and attention to details.
