Applying deep learning for change detection
Machine learning algorithms can help solve various problems in remote sensing, such as hyperspectral image classification, semantic 3D reconstruction and object detection. Deep learning can also be applied in terrain change detection. It is the process of spotting respective changes over time by observing the area of interest at different times. Such change detection can be applied in agriculture to observe fields’ fertility over time, monitor deforestation, and city planning.
Automated damage detection is a task that can also be approached as a supervised change detection problem. Previous studies in this field show successful applications of image segmentation in order to solve this problem. Using a pair of images that correspond to the same set of coordinates before and after a hazard (over a short period of time, assuming no structural patterns have not been changed), it is possible to identify image masks of structures in the pre-event image and then compare each mask with the post-event image.
Given that Ukraine is currently experiencing ongoing bombing from russia, we decided to test whether the model trained on natural disaster data can be used to assess damage in destroyed areas of Ukraine.
Dataset details
We have used two datasets: xView2 xBD dataset and a manually annotated dataset using Google Earth and Maxar public imagery. The first one was chosen because it is one of the largest open-source datasets for satellite damage classification. We use this dataset both for training and testing purposes. The second dataset consists of buildings’ destruction during the russo-Ukrainian War in 2014 and the 2022 russian invasion of Ukraine.
1. xView2 xBD dataset
The xBD dataset used imagery from Maxar’s Open Data program. The Open Data program provides high-resolution satellite imagery for the research community to engage in emergency planning, risk and damage assessment, monitoring of staging areas, and emergency response. It includes crowdsourced damage assessments for major natural disasters over the globe.
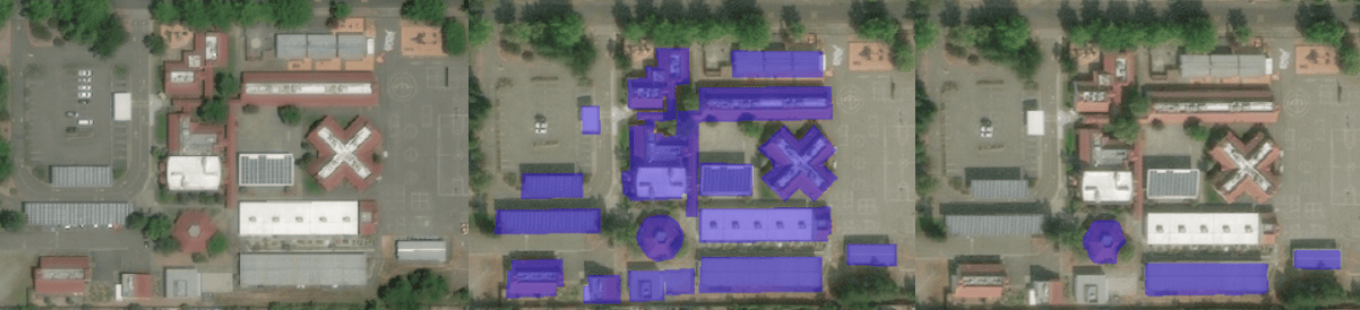
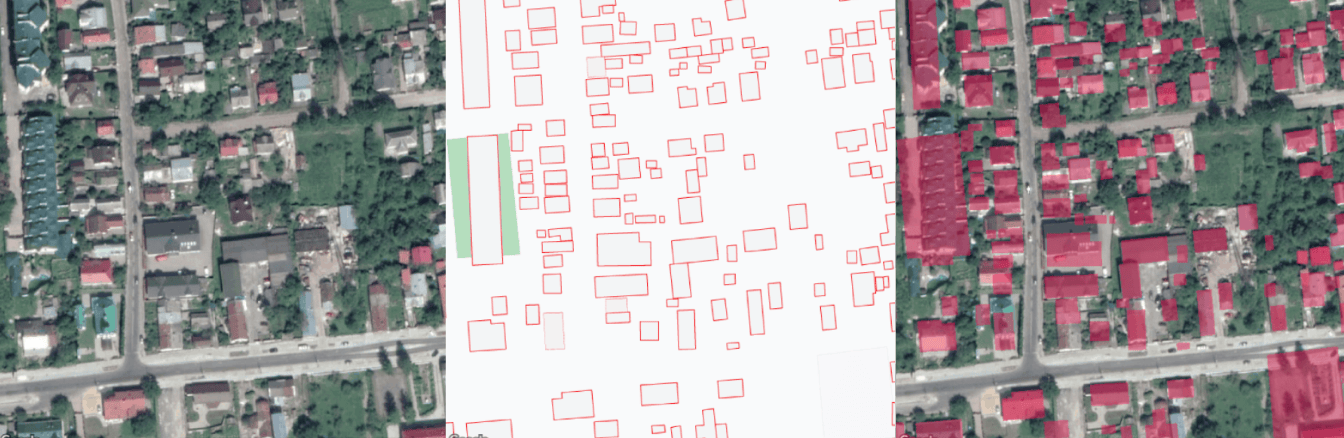
The dataset was manually annotated with polygons and corresponding damage scores for each building on the satellite image. It consists of 18,336 high-resolution satellite images from 6 different types of natural disasters worldwide, with over 850,000 polygons covering over 45,000 square kilometers. The data was gathered from 15 countries and contained pairs of images before (”pre”), and after (”post”) the natural disaster had occurred. All images have a resolution of 1024×1024. Also, the dataset is highly unbalanced and is skewed towards the “no-damage” class. Each pair of images contains a list of polygons (buildings) and a corresponding score from 0 to 3 based on the severity of the damage (after a disaster) for each polygon.
Figure 1: Information about the labels of the polygons in xBD dataset.
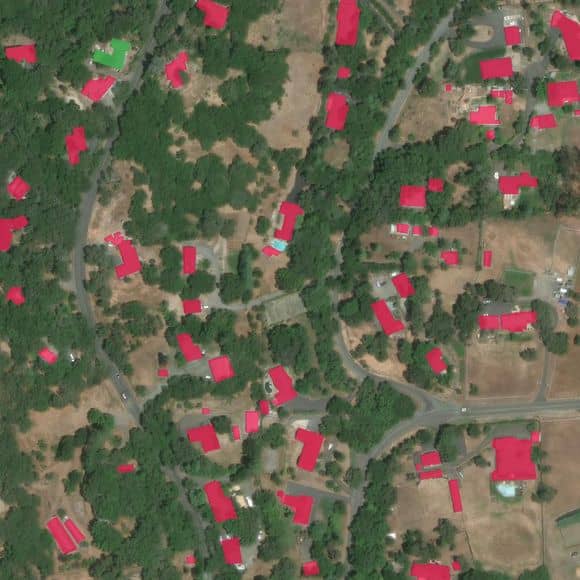
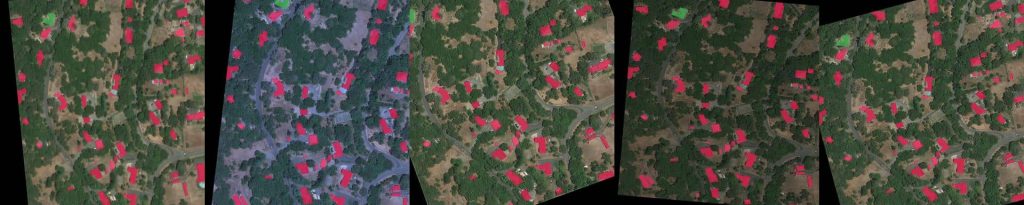
In the figure below, in left-to-right order, you may observe the satellite imagery collected before and after the disaster and the corresponding ground truth mask. The color of the buildings represents the level of destruction, where blue is “no-damage” and red is “totally-destroyed.”