
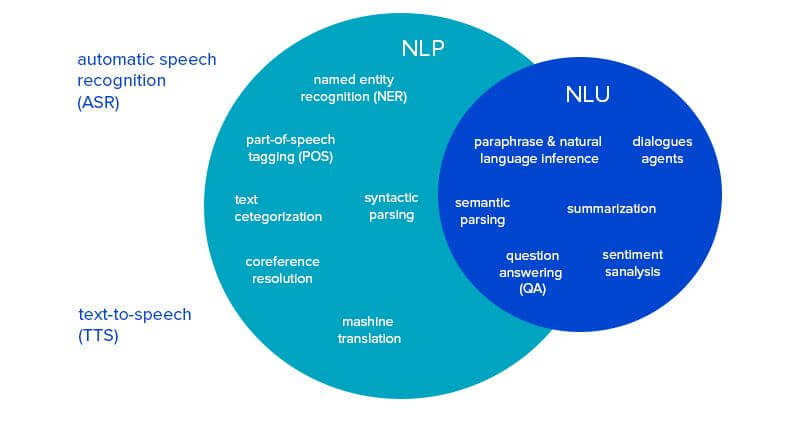
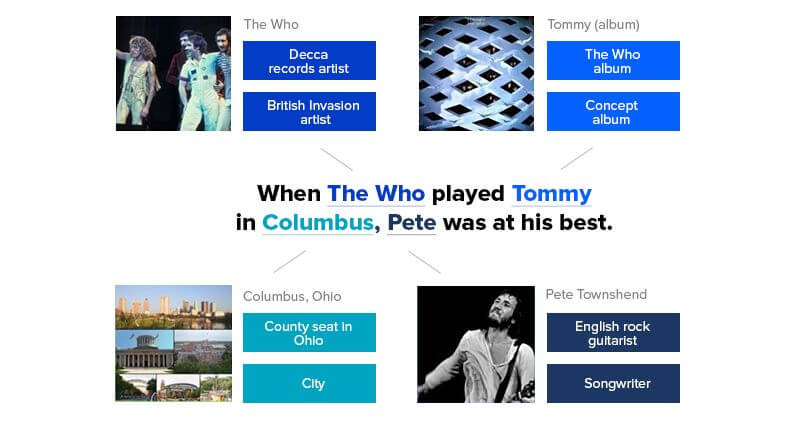
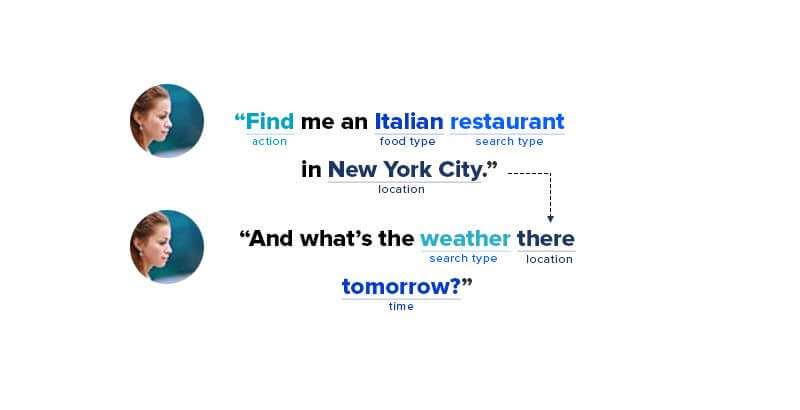
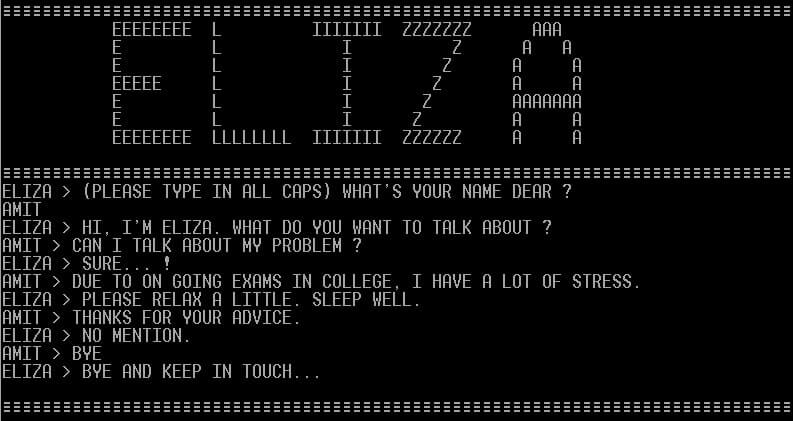

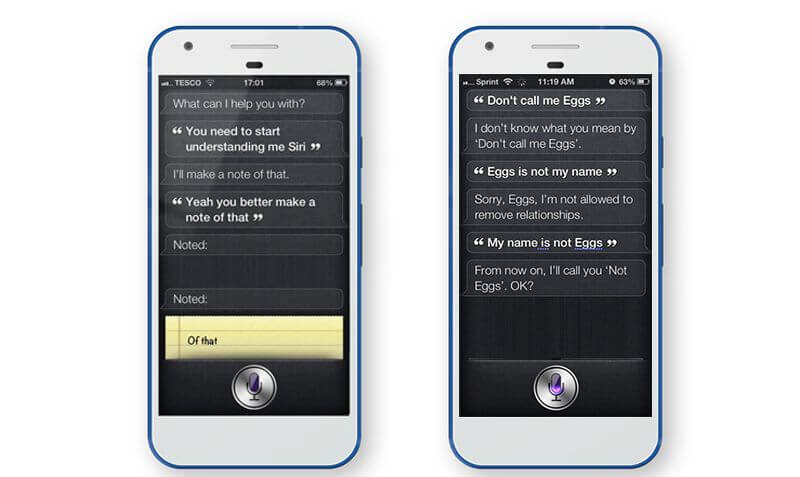

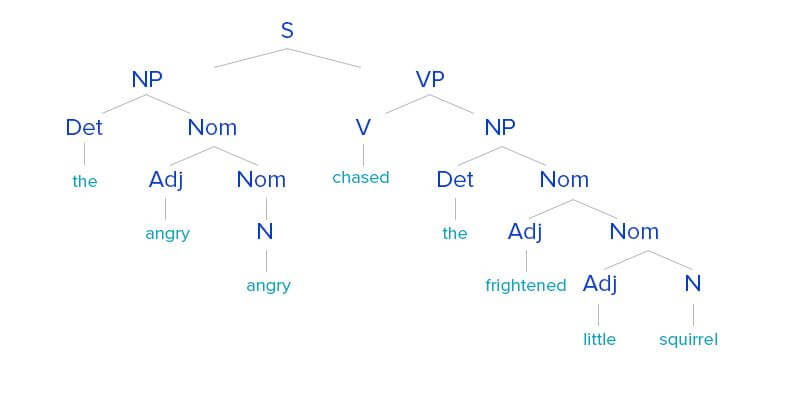
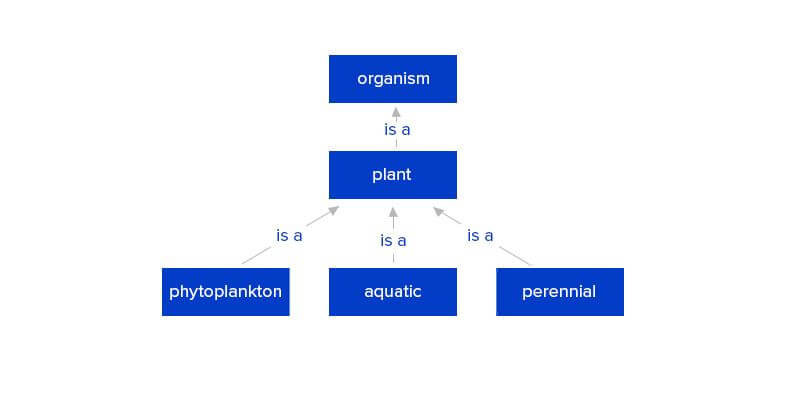
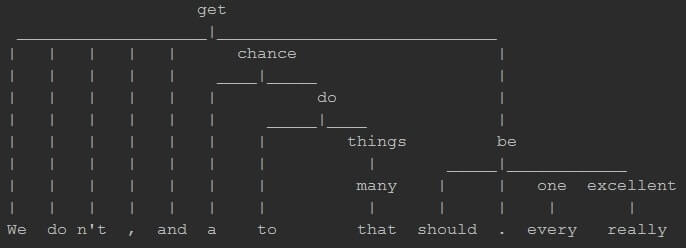






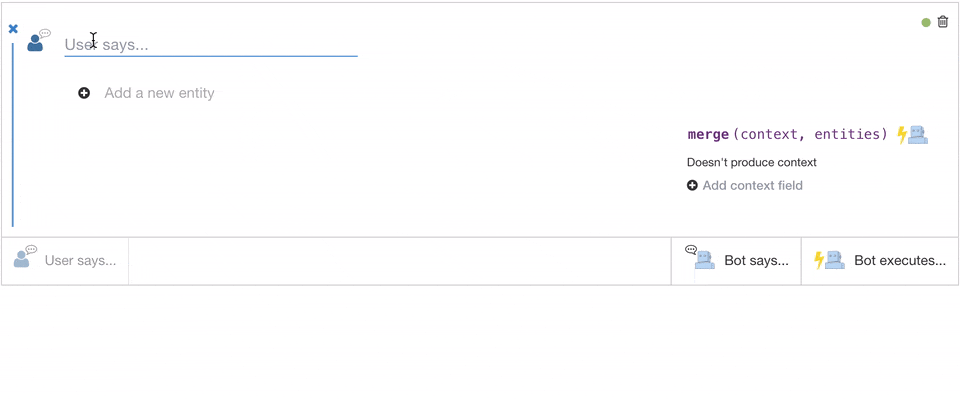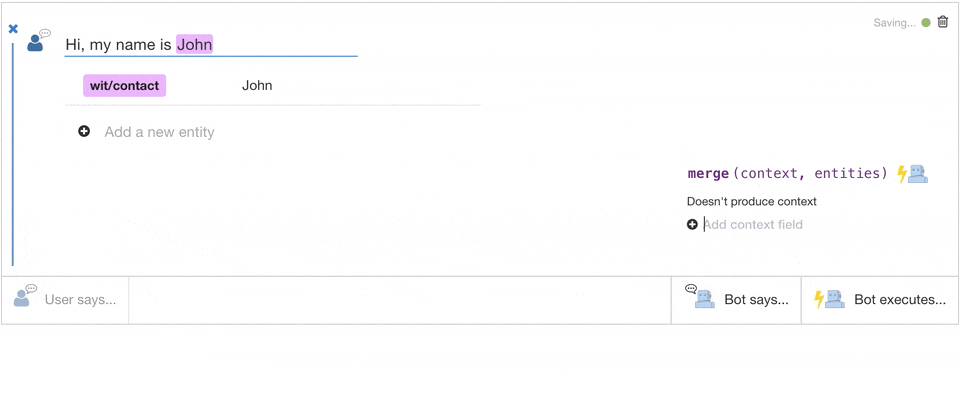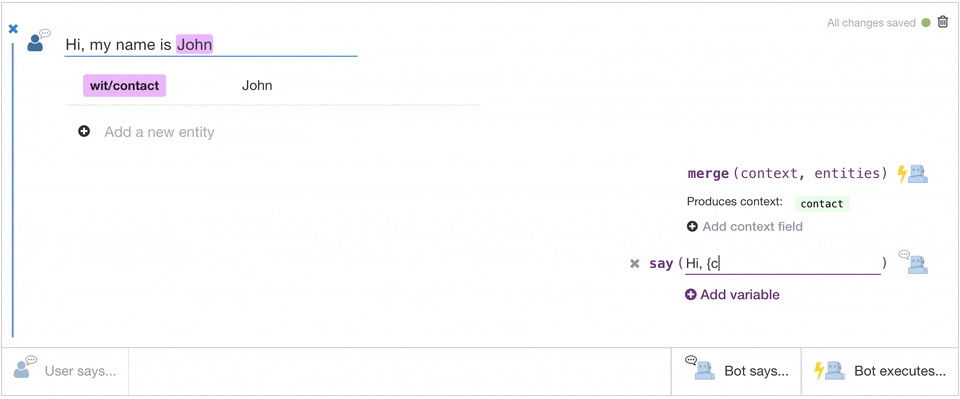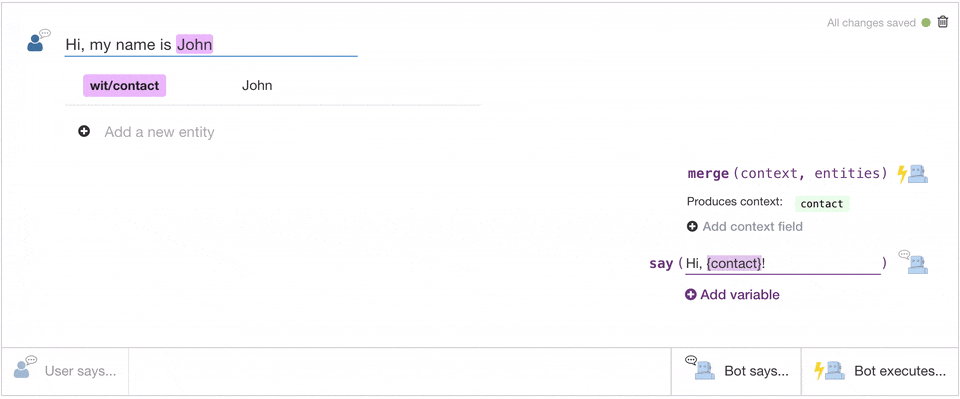

Related Insights








The breadth of knowledge and understanding that ELEKS has within its walls allows us to leverage that expertise to make superior deliverables for our customers. When you work with ELEKS, you are working with the top 1% of the aptitude and engineering excellence of the whole country.

Right from the start, we really liked ELEKS’ commitment and engagement. They came to us with their best people to try to understand our context, our business idea, and developed the first prototype with us. They were very professional and very customer oriented. I think, without ELEKS it probably would not have been possible to have such a successful product in such a short period of time.

ELEKS has been involved in the development of a number of our consumer-facing websites and mobile applications that allow our customers to easily track their shipments, get the information they need as well as stay in touch with us. We’ve appreciated the level of ELEKS’ expertise, responsiveness and attention to details.
