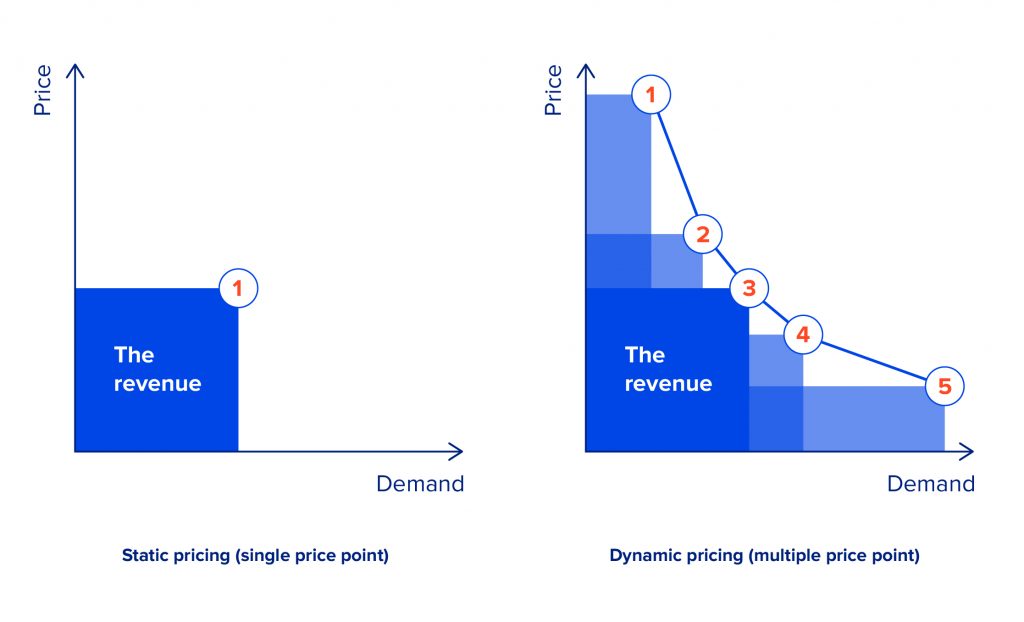
Dynamic pricing for e-commerce: benefits
In today’s e-commerce landscape, many merchants use flexible pricing to stay competitive. Here are some key advantages of dynamic pricing in e-commerce:
- Stay ahead of competitors. Automatic monitoring of your competitors’ prices allows you to quickly adapt to the dynamic environment and gain the lead in the marketplace.
- Increase in profits. After implementing dynamic pricing, Best Buy saw an uptick in sales of 25%. By analysing the market, you can adjust the price of a product to generate more revenue. If the demand for a product is low, you can boost it by lowering the price, and if it is a peak season for a product, you can increase the price without altering your sales volume.
- Gain market insights. Continuous monitoring of the market enables you to stay aware of prevailing market trends and get insights into consumer behaviour, which can lead to better decision-making.
Dynamic pricing for e-commerce: turning challenges into success
While dynamic pricing has many advantages, the strategy itself cannot entirely eliminate the uncertainty regarding consumers’ responses to different prices. In practice, tackling this problem requires the efficient use of sales data.
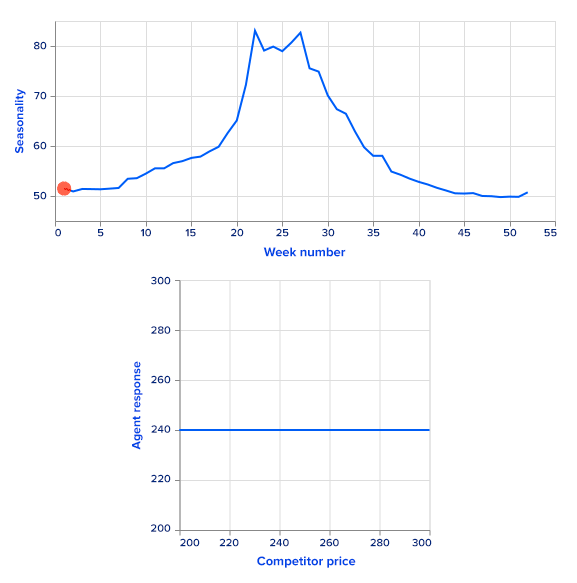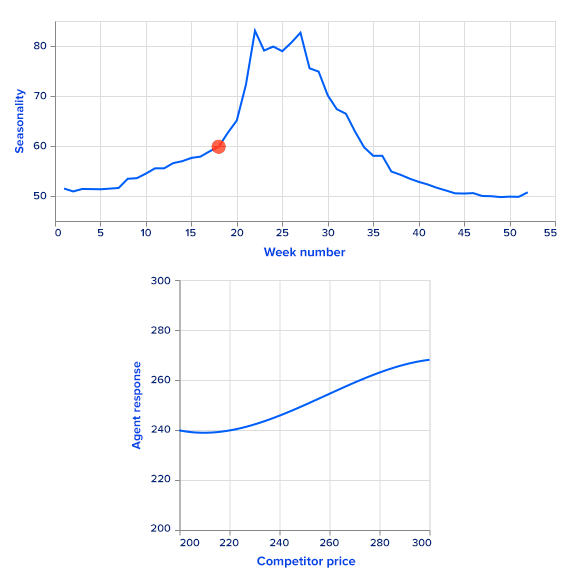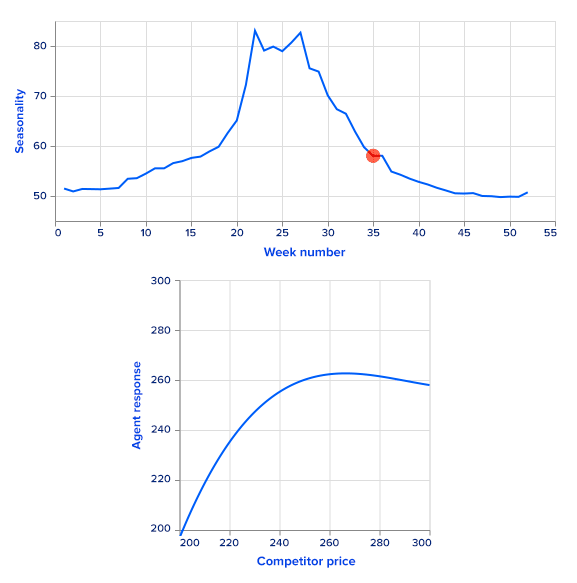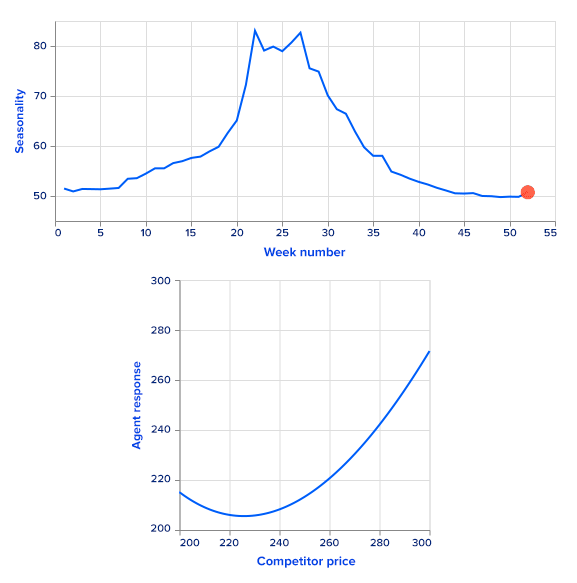
Sales data is time-series data that contains prices along with respective sales and other features that could be useful in driving sales (like inventory, product seasonality, listing, etc). It is an input that a company should provide to build a dynamic pricing engine.
As it is hard to measure agent performance in real life, in this article we present an artificial example, together with theoretically optimal prices for comparison purposes. There are many different approaches for training agents to choose the optimal price for a specific time period. We start the process of building a dynamic pricing system by constructing a sales prediction model that takes as an input a market state and outputs estimated sales. This model is trained on sales data exploiting time series analysis and machine learning methods. An important note here is that the price must be in a set of input features for a prediction model. Moreover, it should have high enough feature importance.
There are two possible approaches for defining a pricing strategy when using a prognostication model:
Optimisation approach.
This is simple one-step optimisation. Using the forecasting model, you can set different prices and see how they will affect sales and income. This is a one-variable optimisation problem over a continuous interval, which is defined by a minimum and maximum price.
Since a prognostication model could be non-parametric and use non-differentiable operations, gradient-based optimisation techniques are not applicable. That is why a typical solution is to discretise a continuous interval into a countable number of possible prices and choose the price that leads to the highest income or another objective. An additional advantage of this method is that it naturally avoids the problem of falling into a local minimum.
The drawback of this approach is that it is rather greedy. In other words, it considers only income in a current timestamp rather than cumulative income over a more extended period, which is a better choice for maximisation.
Reinforcement learning (RL).
An alternative approach, and one that solves the problem of greedy decision-making, is using reinforcement learning methods. It considers associativity between the succussive pricing stages, thus being non-greedy with respect to current timestamp income, but greedy with respect to cumulative income. For example, it may be beneficial to set a lower price in the current timestamp, decreasing the possible income to get into a better market state later.
Understanding reinforcement learning basics
Reinforcement learning, or RL, is one of the three primary areas of machine learning, alongside supervised learning and unsupervised learning. Its primary task is to develop algorithms that allow agents to maximise their cumulative rewards while acting in an unknown environment. RL learns what to do (policy) and how to map situations to actions.
The idea of learning by interaction with an environment is very natural and, in some ways, is biologically inspired. As human beings, we continuously interact with the world around us, trying to maximise our reward (satisfaction, acknowledgement, money, etc.).
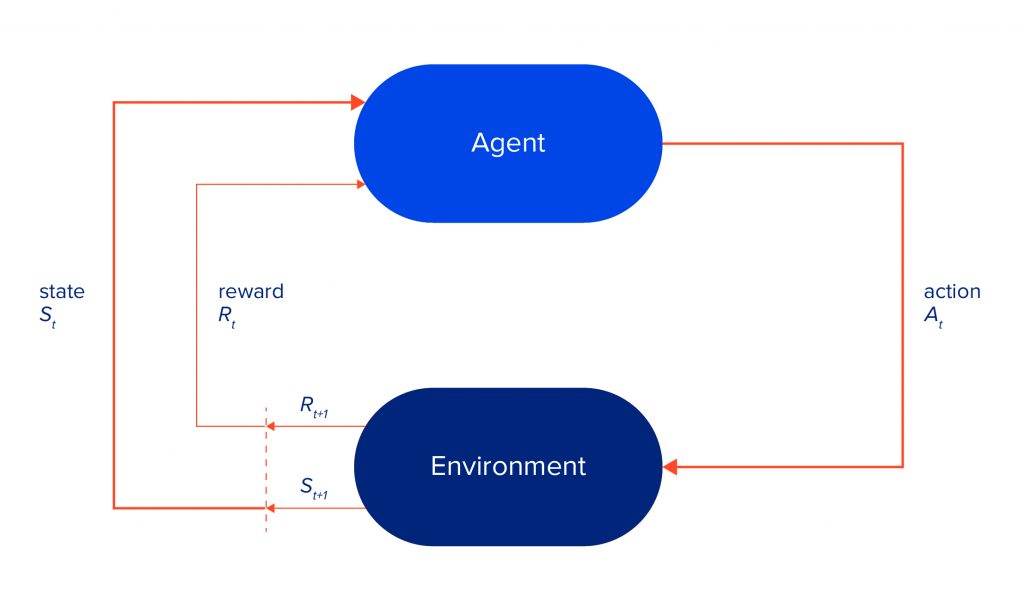
The environment is usually formalised by the Markov Decision Process, or MDP, a discrete-time stochastic control process. It provides a mathematical framework for modelling sequential decision making, in which the agent’s actions may influence future outcomes.
For now, we will restrict ourselves to a finite MDP. It consists of a state space S, action space A, reward space R (a subset of real numbers), and dynamics function p. Sets S, A and R are all finite. Function p defines the dynamics of the MDP.
p(s', r \mid s, a) = P(S_t=s', R_t=r|S_{t - 1}=s, A_{t - 1} = a)
\sum_{s' \in S} \sum_{r \in R} p(s', r|s, a) = 1, for all s \in S, a \in A
More specifically, agent and environment (MDP) interact at each time step t = 0, 1, 2, etc. The agent performs an action a, based on current state s. The MDP receives a and responds with a reward r and the next state s’. Together, they produce the following sequence:
S_0, A_0, R_1, S_1, A_1, R_2, S_2, A_2, R_3, ...
The overall process can be visualised as shown in the picture below.