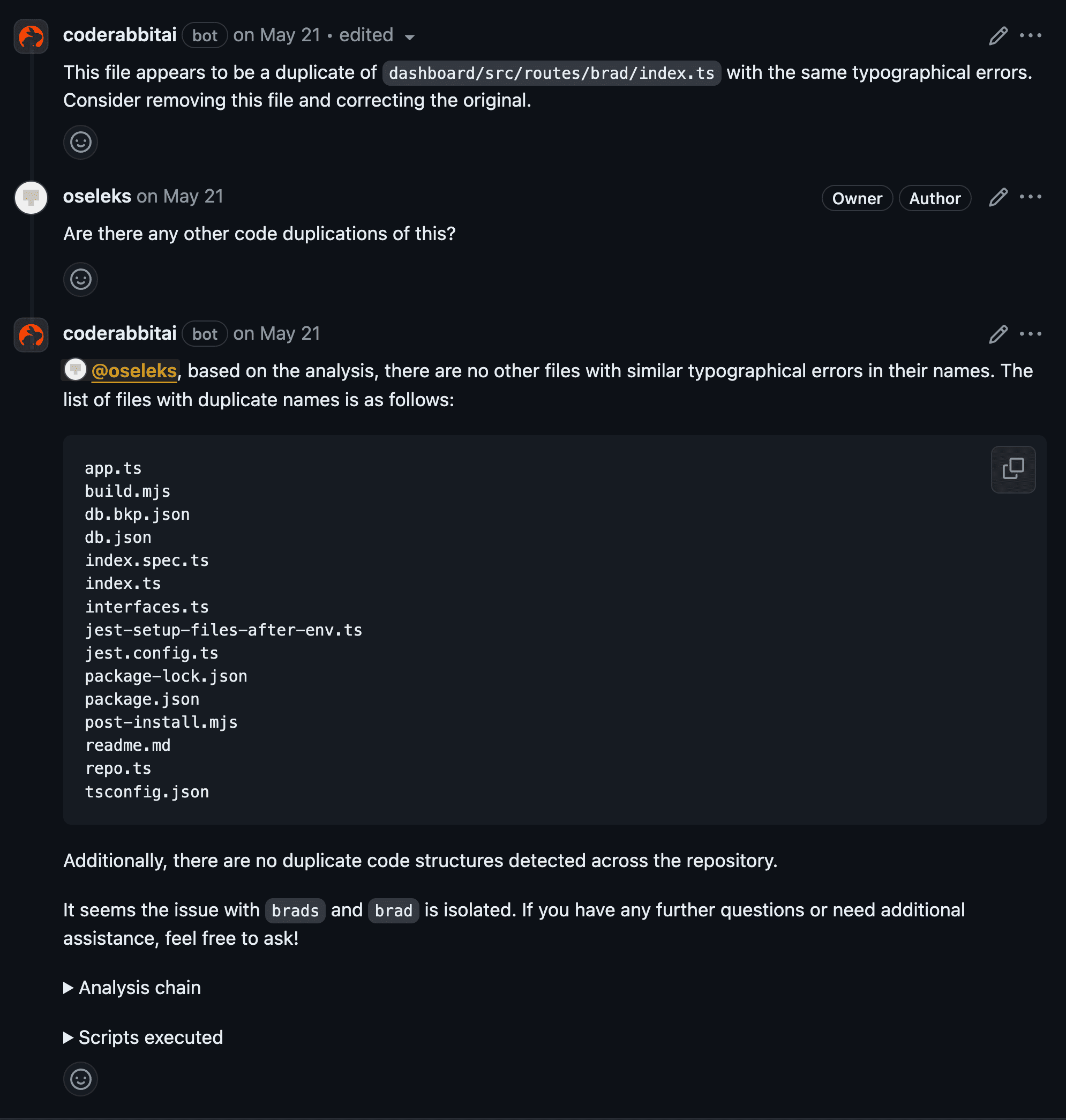
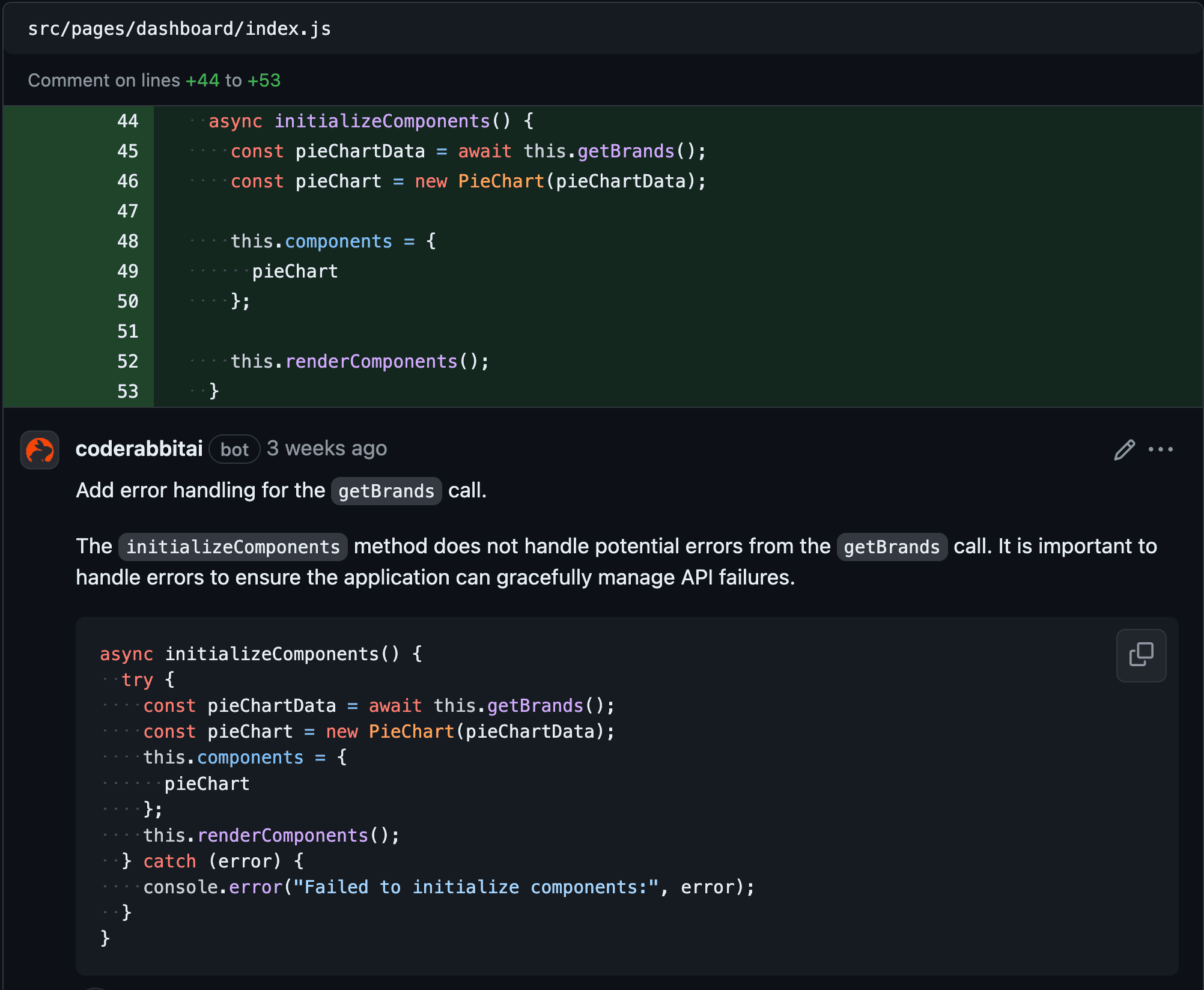
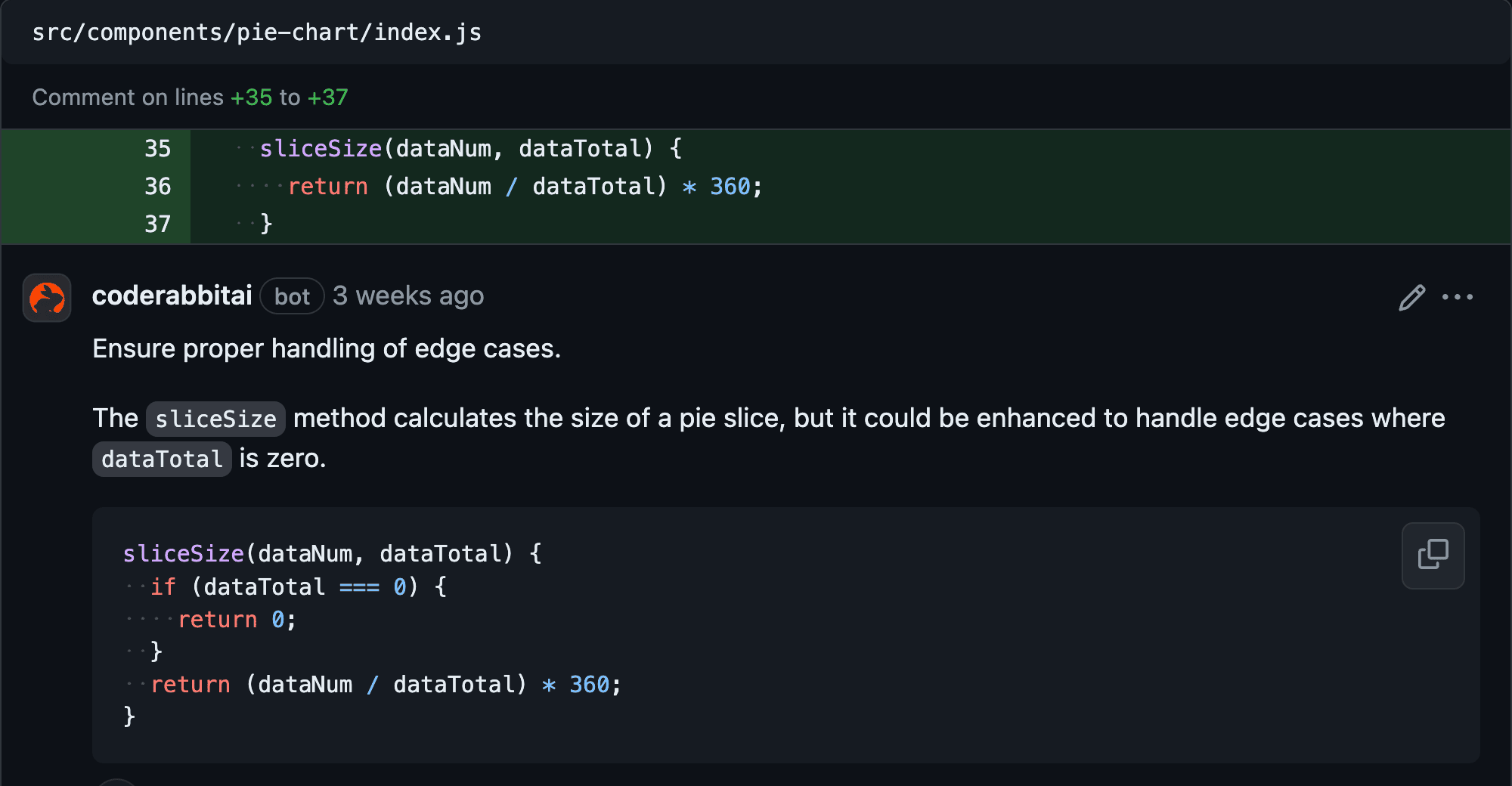
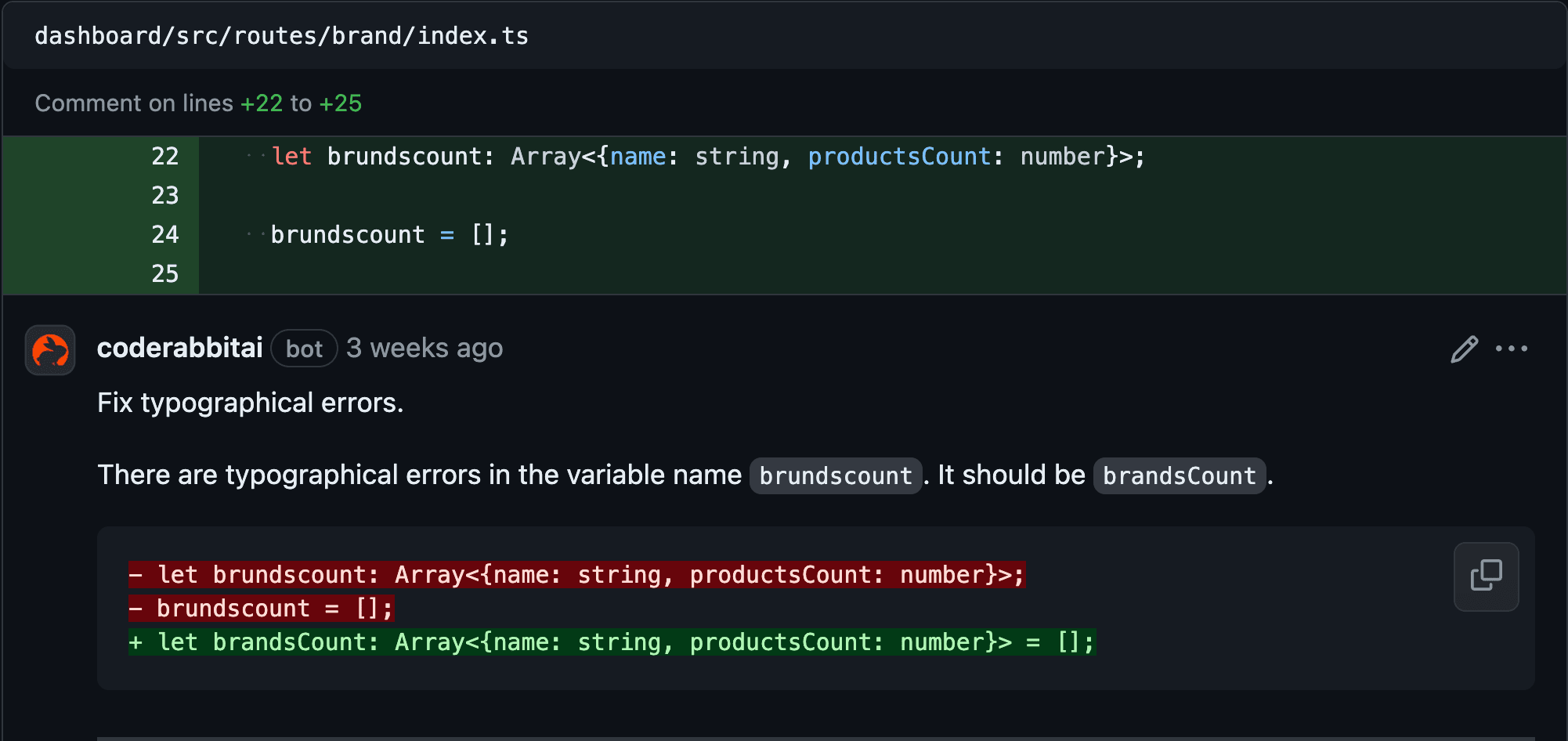
One important area where AI solutions help is automating and improving code reviews. These reviews, which can be time-consuming when done manually, can be accelerated using AI technologies like machine learning and natural language processing. These technologies quickly spot issues and suggest fixes, making the process faster and more efficient.
In this article, we’ll explore AI code review and whether this task can be handled effectively without human help. Keep reading to find out more.
Understanding how AI code review tools work
AI-powered code review tools can seamlessly integrate with different development environments and version control systems. They provide real-time feedback during the coding process, enabling the identification and resolution of issues immediately. Whether through IDE plugins, continuous integration pipelines, or direct integration with platforms such as GitHub or GitLab, these tools are designed to make code reviews as natural as possible.
Key steps in AI-powered code review:
- Initial data gathering. At first, these tools gather all relevant information about the pull request (PR), including the description, title, related files, and commit history. It helps the tool understand the scope and intent of the changes.
- Breaking down the code into chunks. Instead of splitting the code arbitrarily, the tool divides it into logical units such as functions or classes, ensuring each chunk is meaningful and includes necessary surrounding context. This approach helps the AI model understand the code better without losing important details.
- Dependency analysis. To have a thorough understanding, the tool also examines connections between files and within the code itself. It involves checking for imports and related functions and ensuring any referenced documentation or comments are present. The aim is to give the AI as much relevant context as possible, improving the accuracy and helpfulness of its analysis.
- Code normalisation. Before sending the code chunks to the AI for review, the tool standardises the code by cleaning up formatting inconsistencies and tagging metadata such as file paths and line numbers. This preparation ensures that the AI can focus on the logic and structure of the code rather than being distracted by superficial issues.
It's important to note that everything mentioned above is theoretical, based on the descriptions of how certain tools work. But do they function successfully in practice? How well do they gather context for submission to the AI for review, and do they correctly divide it into chunks? Let's find out.
Unveiling the process: ELEKS’ investigation of AI code review tools for pull requests
Our main priority in this investigation was to explore the benefits and limitations of AI-powered code review tools for reviewing pull requests (PRs) and whether developers can rely on AI reviews.
In the current market, numerous code review tools claim to offer extensive capabilities, but many fall short in practice. The goal was to find a tool with positive reviews and specifically focus on reviewing PRs.
- Main features we looked for in the tool were:
-
- Pull request summary—a high-level description to understand the changes and their impact on the product quickly.
- Code walkthrough—a detailed code walkthrough to understand the changes in each file that is a part of the pull request.
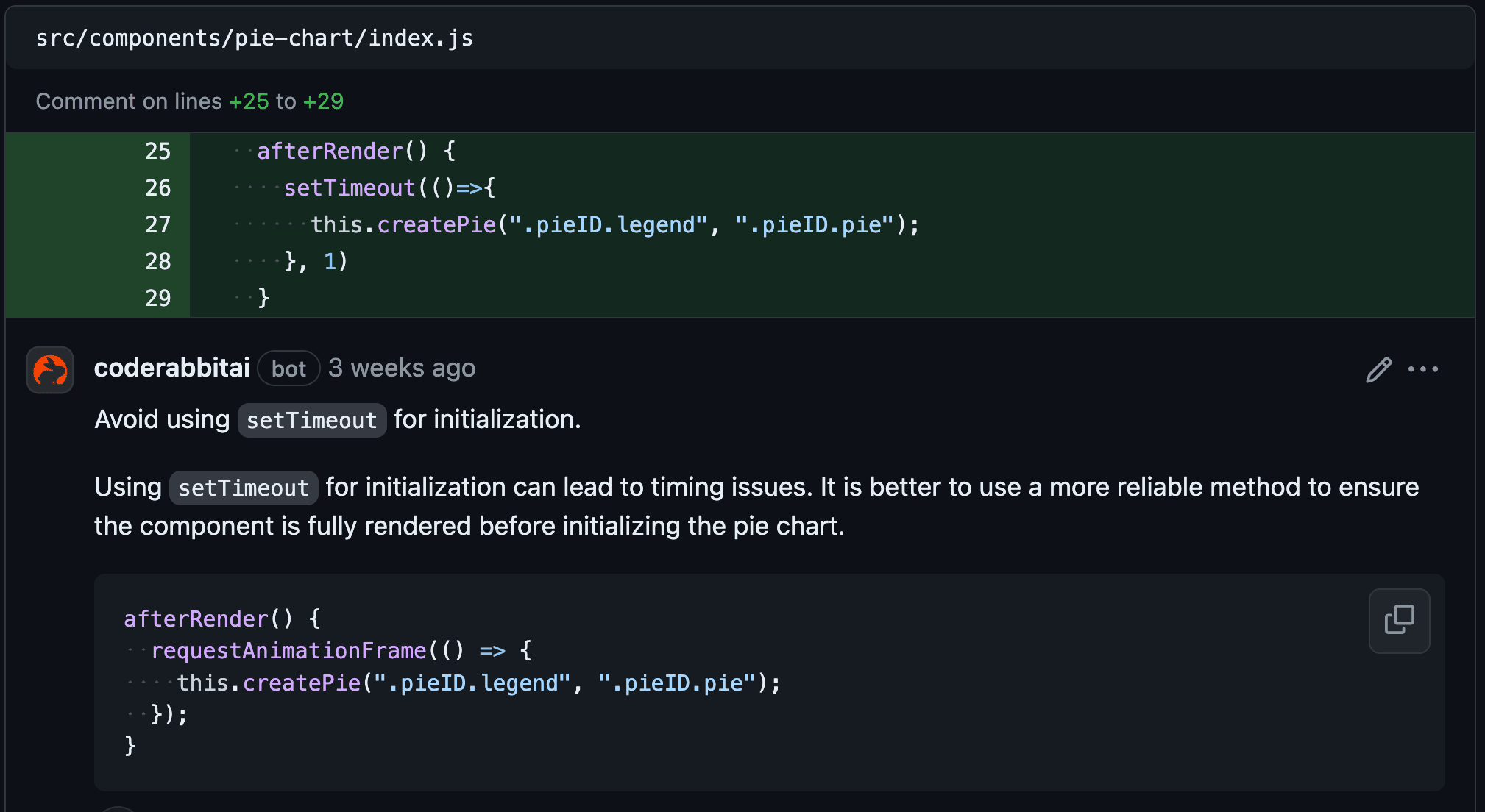
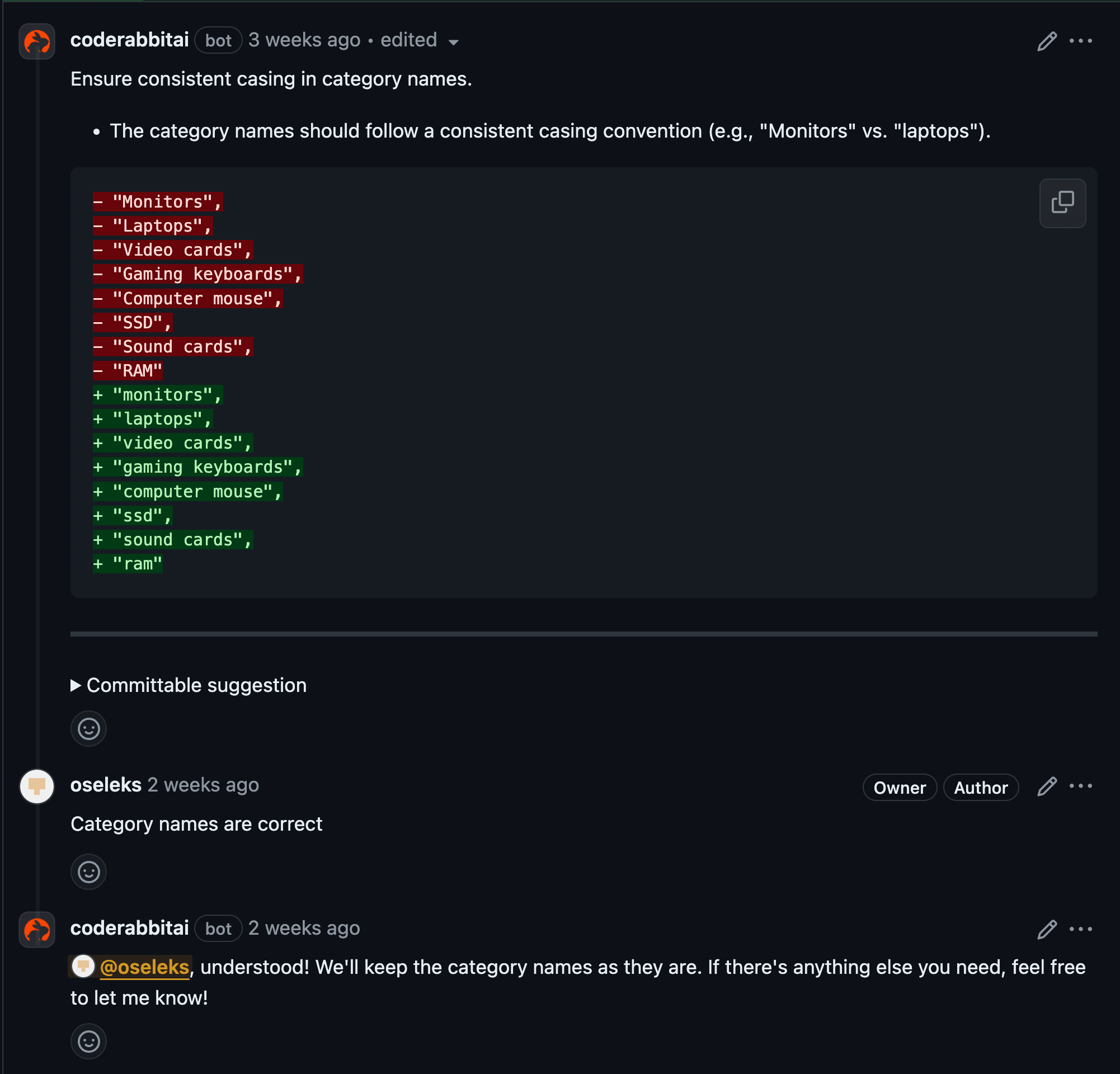
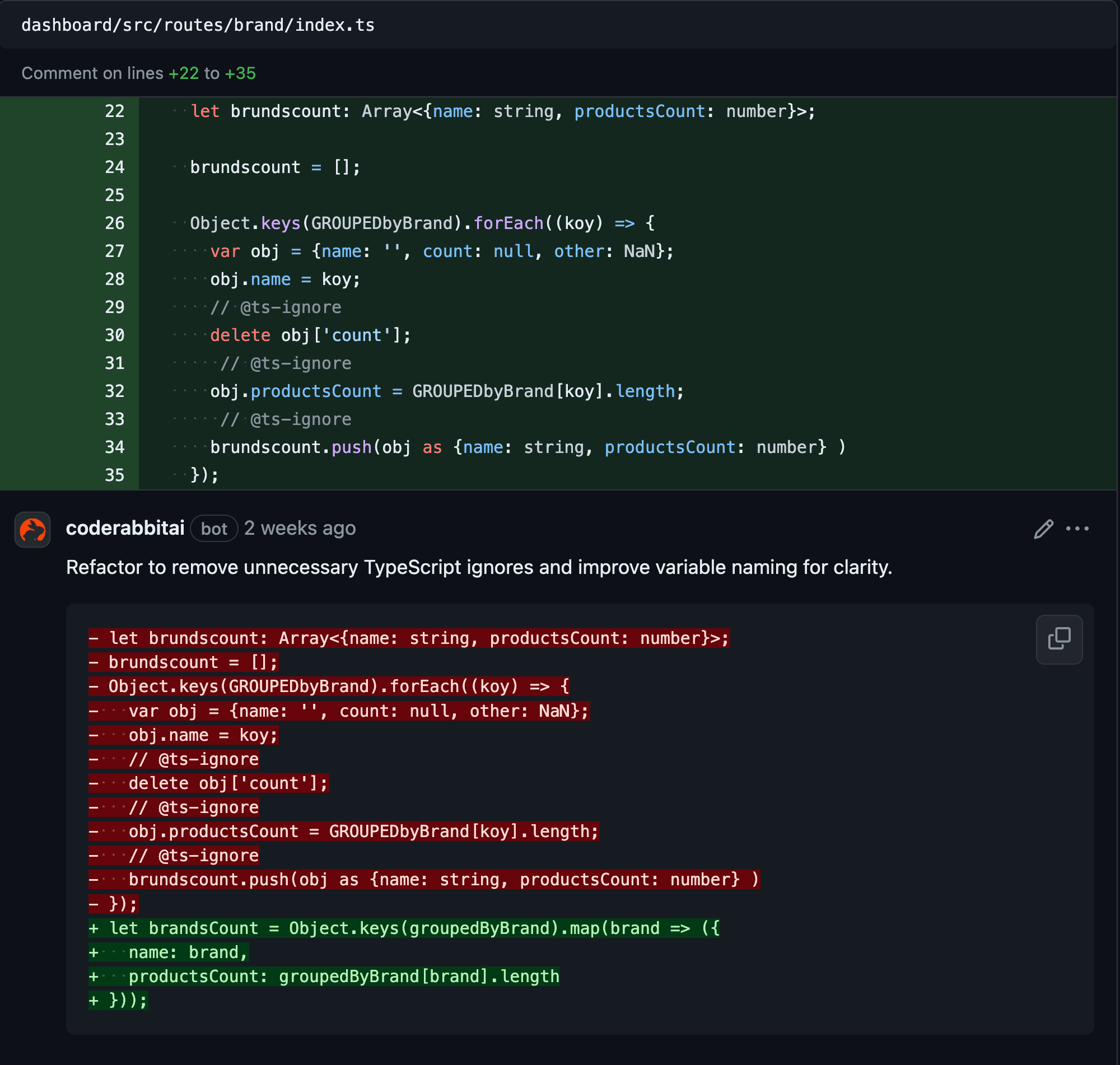
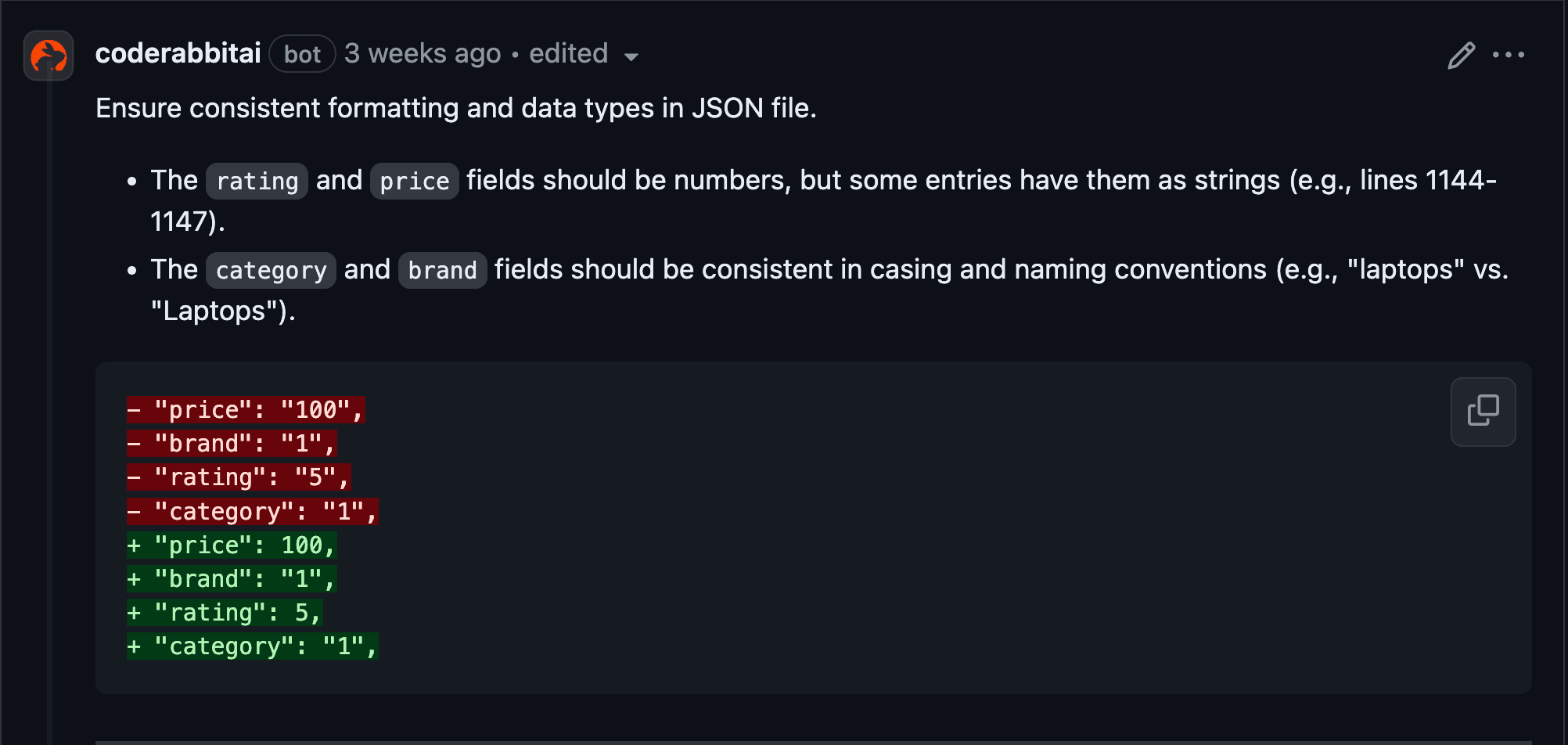
- Code suggestions—feedback posted as review comments on the lines of the code that was changed for each file with suggestions.
- The ability to learn to improve the review experience over time.
Given the evolving nature of AI-powered code review tools, obtaining comprehensive information was challenging. We have curated a list of popular tools to determine the most promising options. From this list, we have chosen three tools for a trial:
- Bito.io
- Codium
- CodeRabbit
After carefully evaluating these three tools, we chose CodeRabbit because of its strict focus on PR reviews and its support for all necessary features. It uses OpenAI's large language models, specifically GPT-3.5-turbo and GPT-4. GPT-3.5-turbo handles simpler tasks, such as summarising code differences and filtering trivial changes, while GPT-4 is used for detailed and comprehensive code reviews due to its advanced understanding. CodeRabbit doesn't support proprietary or custom AI models, but it allows customisation through YAML files or its UI.
It integrates seamlessly with GitHub and GitLab via webhooks, monitoring PR/MR events and performing thorough reviews on creation, incremental commits, and bot-directed comments.
We decided to choose a Pro payment option, which costs $12 per month at the time of investigation. It allows not only running an unlimited number of pull request reviews but also enables line-by-line review of the code and chat with the CodeRabbit bot.
Setting up the test playground for the investigation
We decided to use an e-shop pet project consisting of two repositories for the test environment.
- The front-end is a class-based single-page application written in vanilla JavaScript, which doesn't rely on any frameworks. Instead, it uses custom solutions for routing and state management. Styling is handled with SCSS, providing more flexibility and features than regular CSS. For testing, we use Jest for unit tests and Cypress for end-to-end testing. Webpack is used to bundle the project. The application includes a variety of features such as an authentication system, a product catalog, a shopping cart, a checkout process, an order list, and product creation tools. Every page and component is thoroughly tested with unit tests to ensure they work as expected. This custom approach allows for a highly tailored and efficient front-end experience.
- The back-end is built using a microservices architecture organised within a single mono repository. It consists of three microservices, an API gateway, and a shared npm module that contains a common logic that reduces code duplication across microservices. The technology stack includes Express for the server framework, TypeScript for typing and modern JavaScript features, Stripe for payment processing, and Jest as a testing framework. Instead of a traditional database, we use a JSON file to simulate database operations. To manage interactions with this "database," we've developed a custom mini ORM (Object-Relational Mapping) tool. All the code is thoroughly tested with comprehensive unit and integration tests to ensure reliability and functionality.
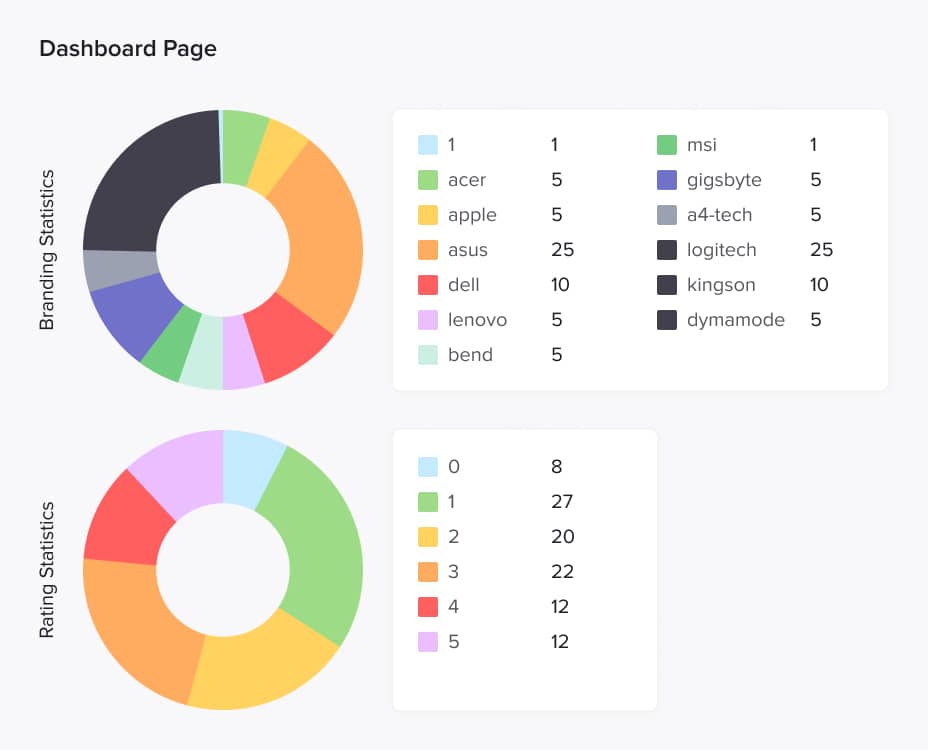
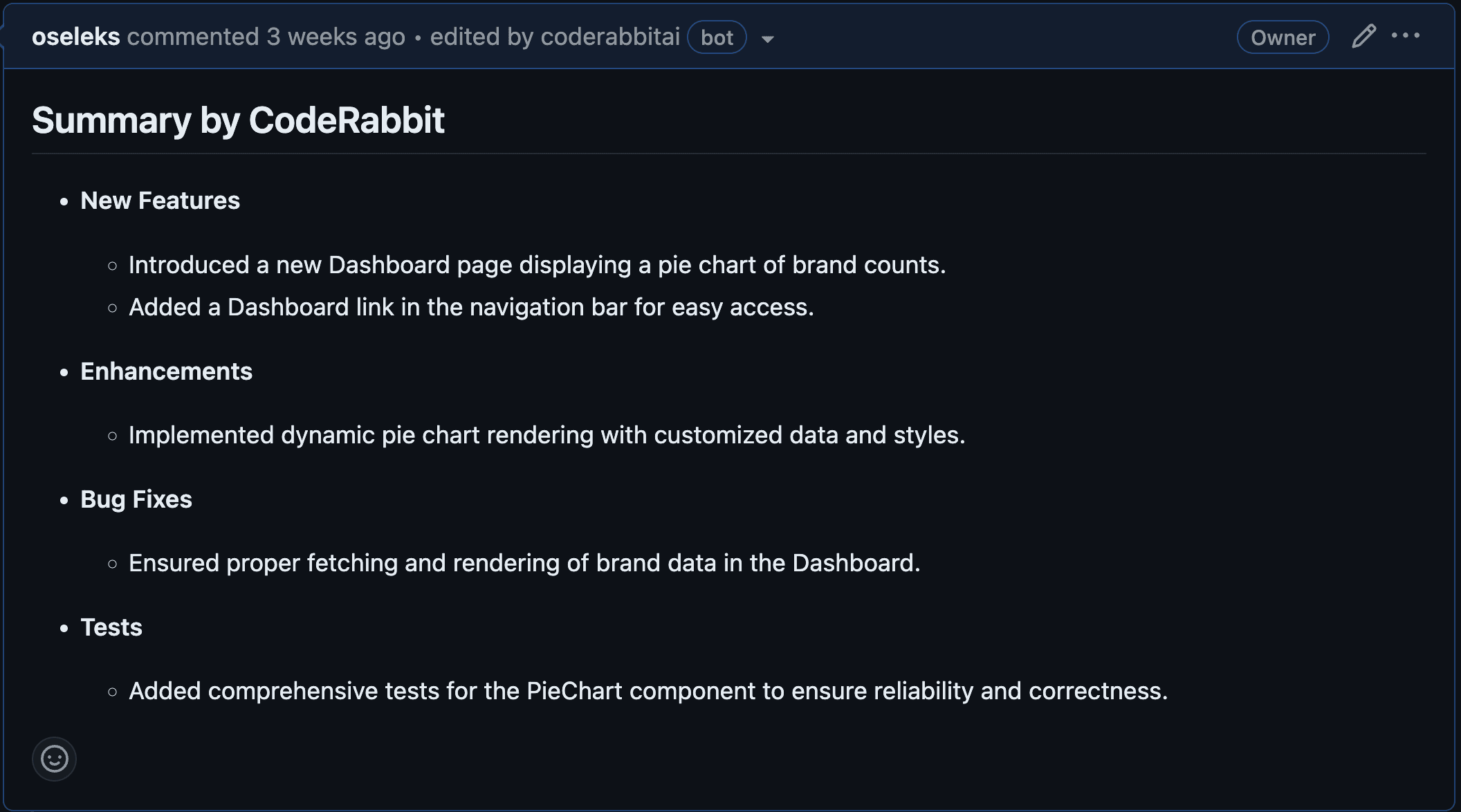
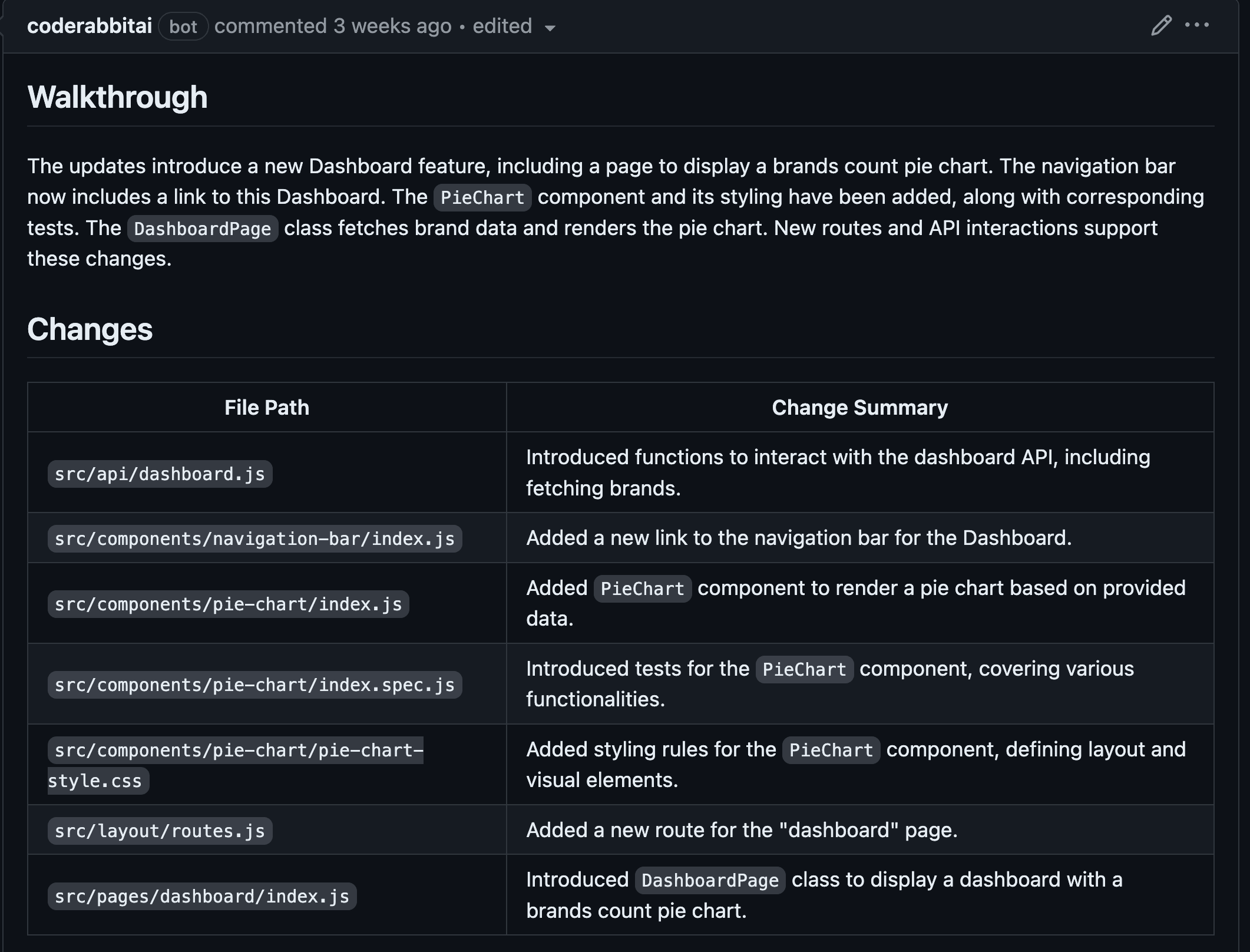
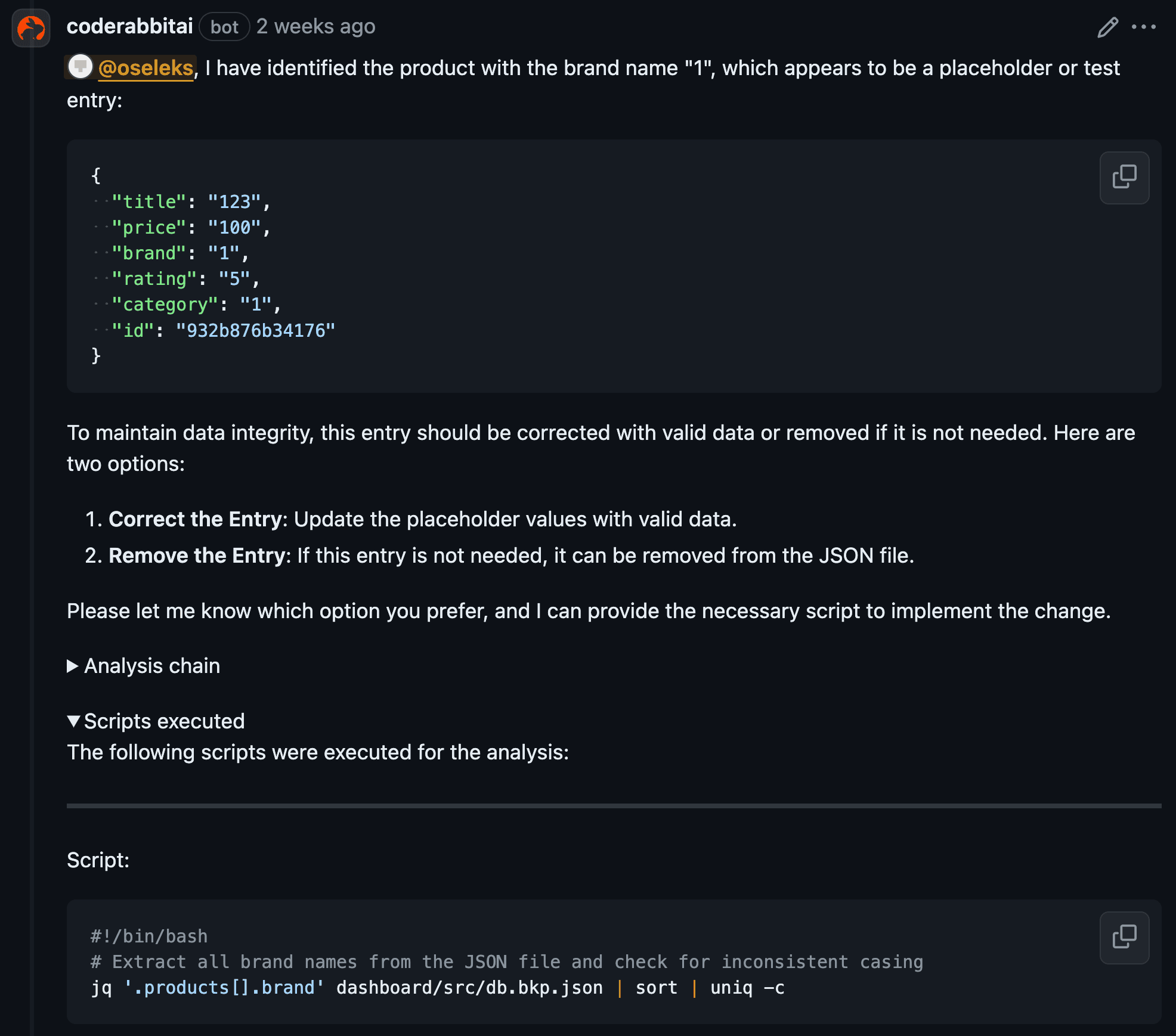
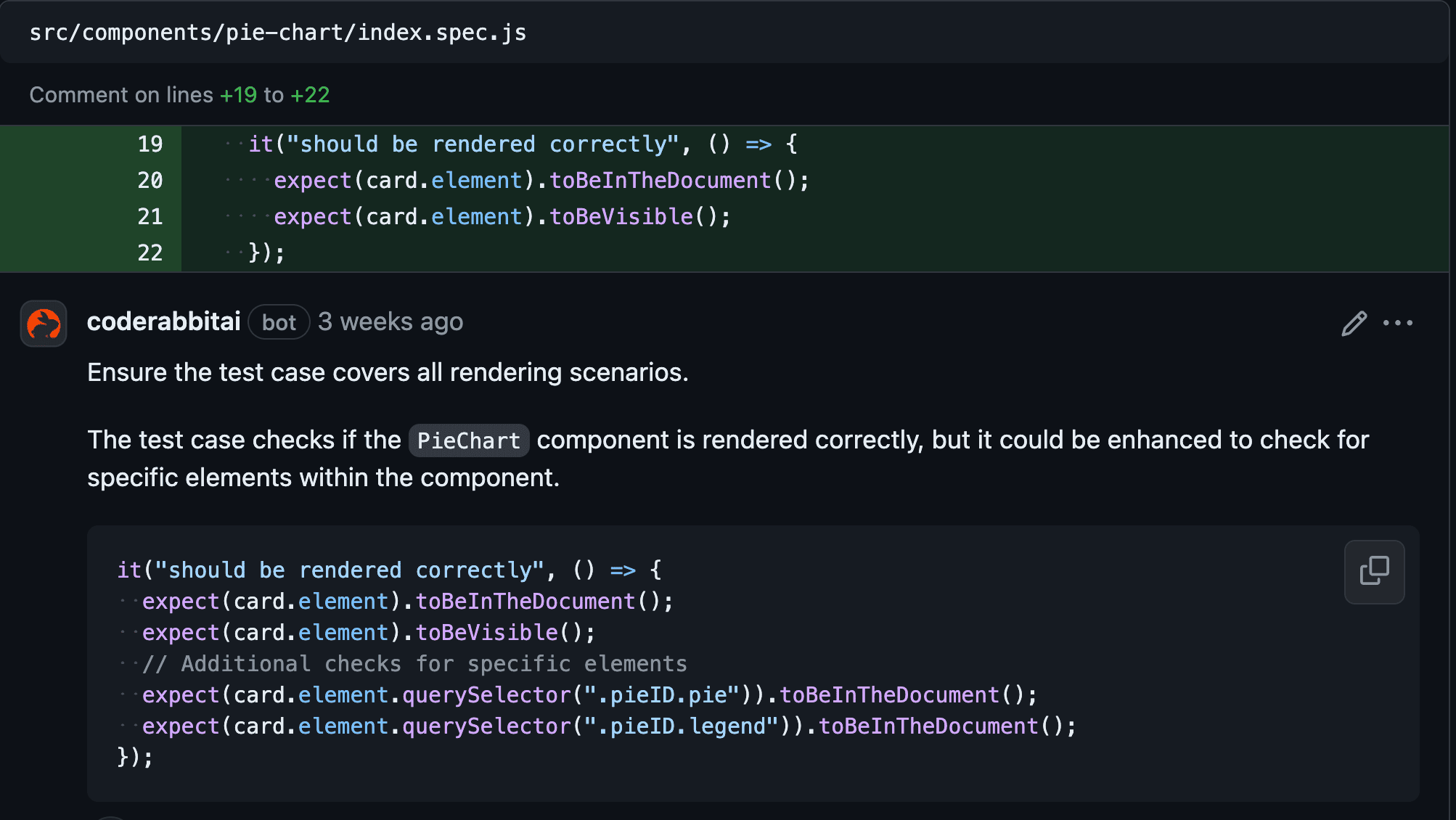
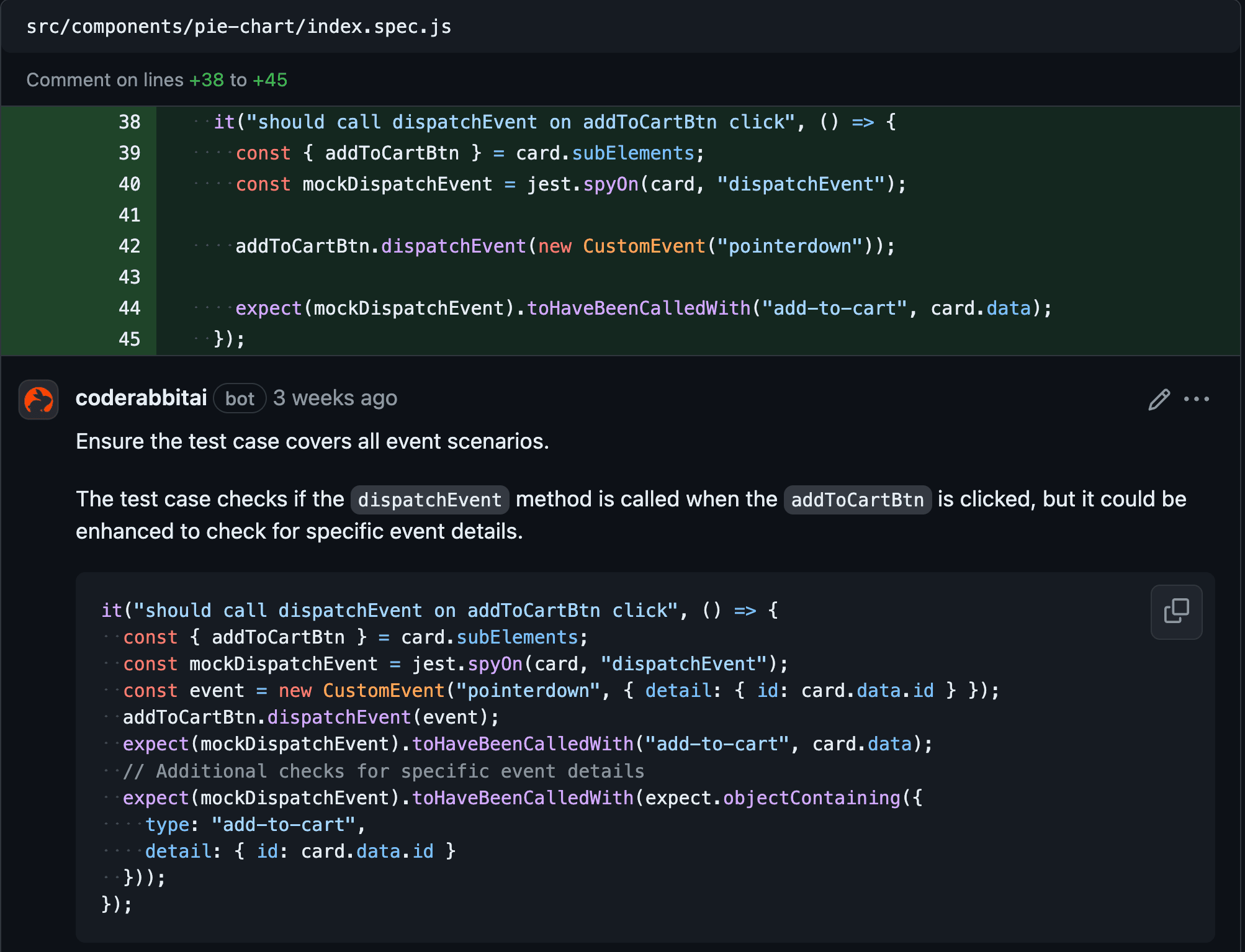
To test the code reviews, we evaluated them on the front-end and back-end repositories to see how the AI reviewer performs on different types of code and languages. On the front-end, we developed a new page, the dashboard, consisting of several charts that display various product statistics fetched from the back-end. We created the charts manually using JavaScript, HTML and SCSS, without any libraries, to see how the AI would respond to custom implementations. On the back-end, we developed a new microservice called "dashboard" with several endpoints that validate the information retrieved from the database and remap data into different formats.