It's no longer a question of whether using LLMs has become a common practice, particularly due to their powerful optimization capabilities. As the AI development field is constantly evolving and companies will continue to adopt LLMs into their workflows, an important question arises: what happens to user data once it's no longer handled locally? Most widely used LLMs operate as black-box models, raising concerns about whether they use user data for training purposes. In practice, while the user's input isn't used for full-scale training, it can still be accessed for limited purposes like model refinement or human review.
A more significant risk is that once this information enters the LLM's pipeline, users have no visibility into where their data is stored, who has access to it, or whether it might be exposed to third parties. These risks have gained significant attention in recent years, creating security guidelines designed for AI systems. One of the most well-known examples of security guidelines is the OWASP Top 10 for LLM Applications. It highlights the common risks like leaking sensitive information, tricking the model with harmful inputs, or using unsafe add-ons. Additionally, OWASP emphasizes the importance of input validation and data sanitization to protect against these vulnerabilities.
Anonymizing data before it reaches LLM: a practical approach
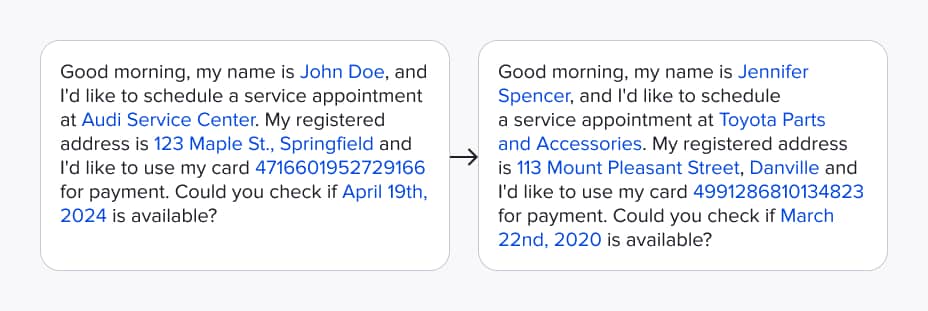
In response to challenges related to the use of sensitive data by LLMs, ELEKS’ data science team developed a local, offline data de-identification tool designed to protect sensitive, confidential, personal identifying information before it reaches an external model. The tool is implemented as a Python package and can be easily integrated into existing workflows. This module is already in active use across several of our internal and client-facing projects, particularly, where deploying large-scale models locally isn't feasible. This tool can be a practical solution for businesses dealing with tight infrastructure budgets, struggling with the limits of lightweight models, or working with highly confidential data. Integrating our data anonymization services allows teams to strike the right balance between productivity and responsible data handling.
However, while spotting sensitive data is common, true anonymization is still a challenge. Many tools are great at finding and tagging personal data, but struggle when it comes to generating realistic, context-aware replacements. Some tools use fake data generators like Faker, which work offline but often ignore the original formatting or lose important context. Others try to solve the problem by sending each sensitive value independently to an external language model to generate replacements, which negates the core objective of protecting user privacy. We weren't trying to reinvent the wheel, so we decided to combine the most effective parts of existing solutions and add the missing pieces they often lack.
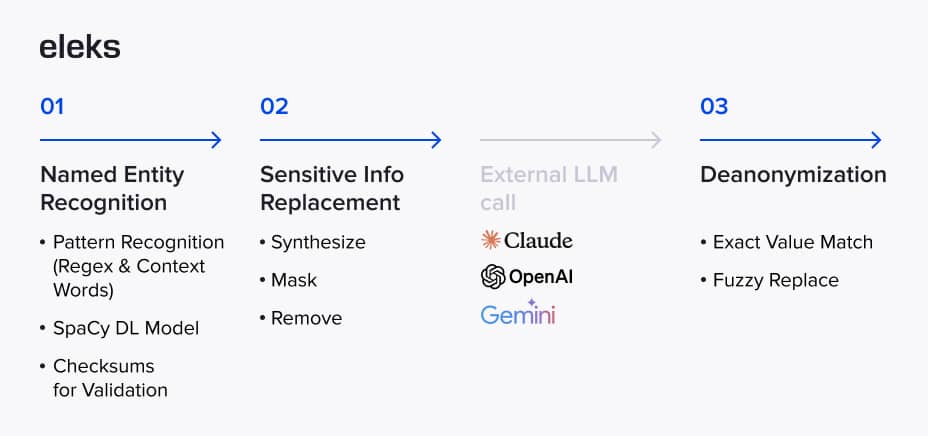
Technical architecture of the anonymization solution
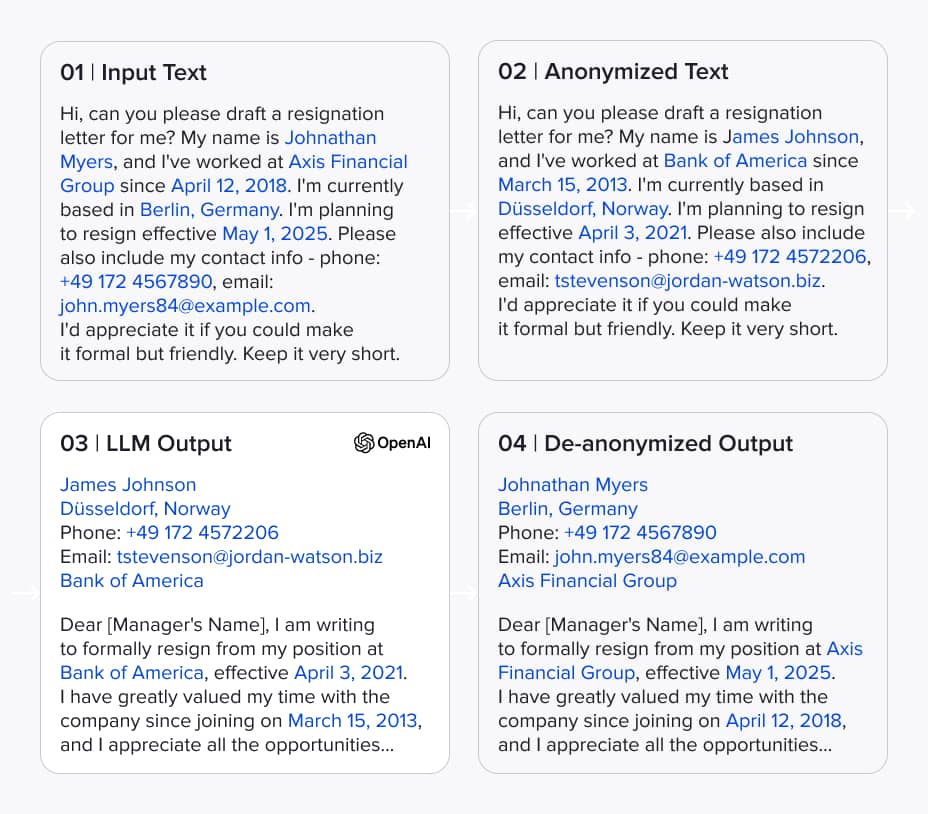
When a user submits text for anonymization, it goes through two main stages:
- Recognition of the named entities
- Replacement of those entities using a selected anonymization strategy.
The process begins with an analyzer that is responsible for detecting potentially sensitive data within the input text. Besides personally identifiable information (PII) such as names and dates, the analyzer can detect a wider range of entities, including addresses, company names, web identifiers, and various types of numerical data, such as cardinals and ordinals. In total, it supports the recognition of around 30 distinct entity types. This component is built on top of the Presidio framework, which combines deep learning-based named entity recognition (NER), regex matching, and context-based enhancement. We've combined and configured its core capabilities to better handle real-world inputs:
- NER: We use spaCy's transformer-based en_core_web_trf model (a fine-tuned RoBERTa). After evaluating alternatives like Stanford's deidentifier, Stanza, and Flair, we found that spaCy offered the best balance of speed and entity coverage;
- Regex: In addition to Presidio's built-in patterns, we introduced custom recognizers to detect a wider range of phone numbers, numeric values (in both digit and word forms), and address formats.
- Context enhancement: To improve confidence scoring, we used spaCy's word stemming and added our parameters to weigh the surrounding context and boost precision.

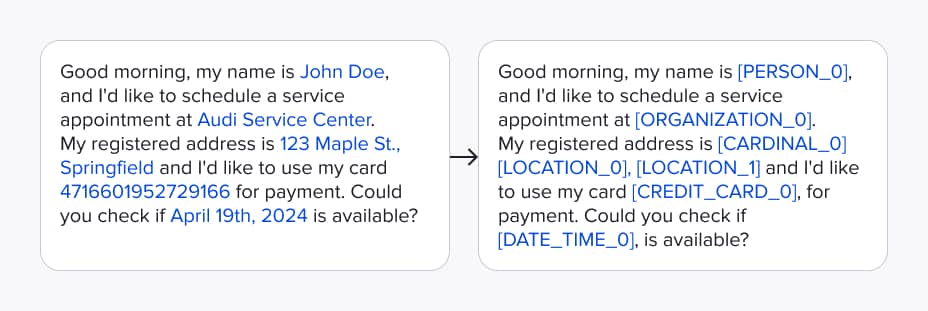
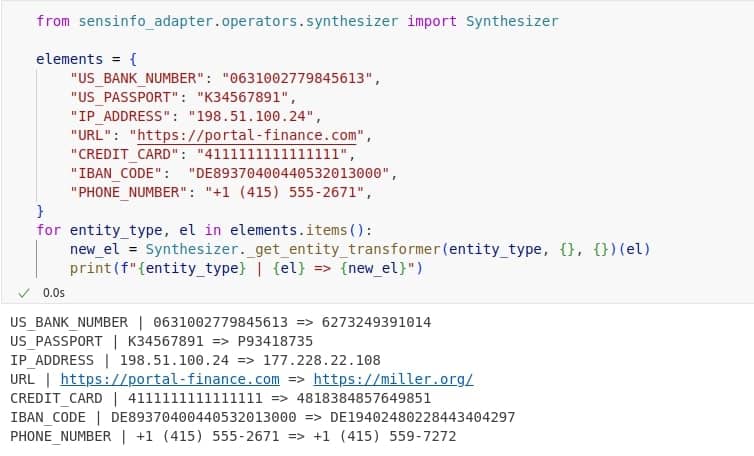
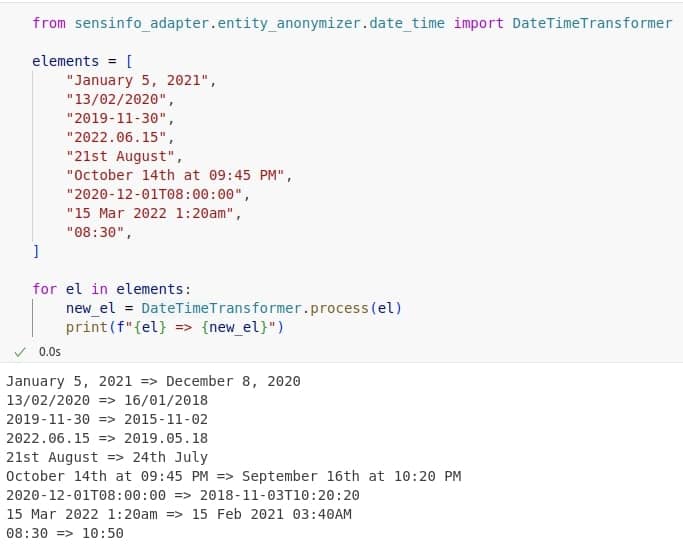
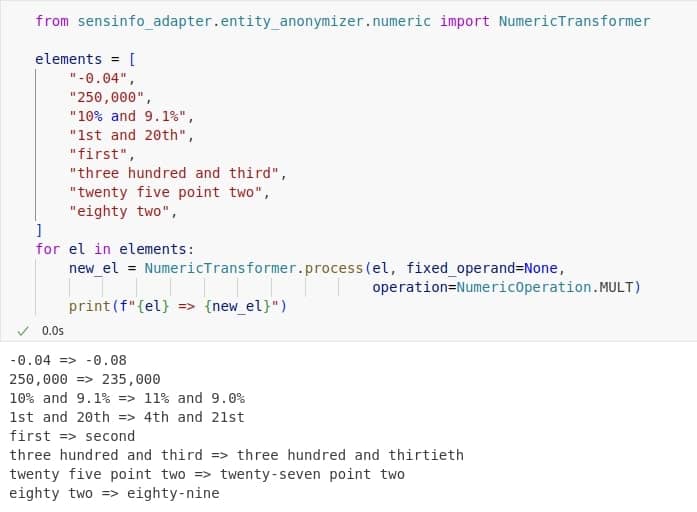
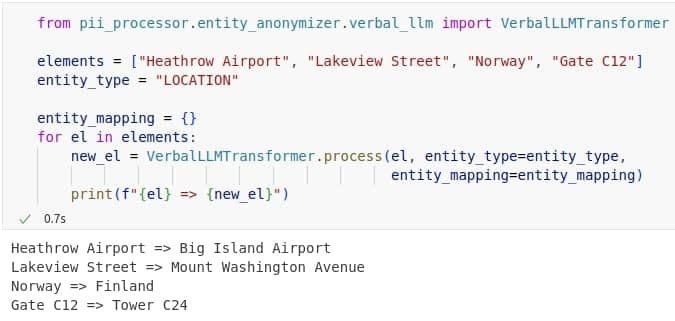
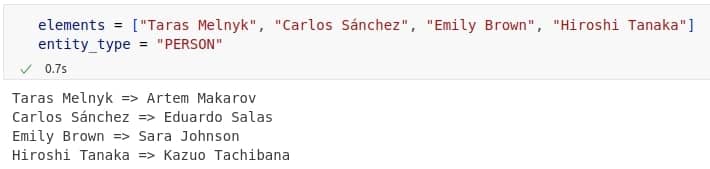
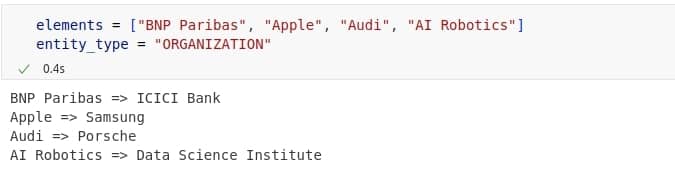
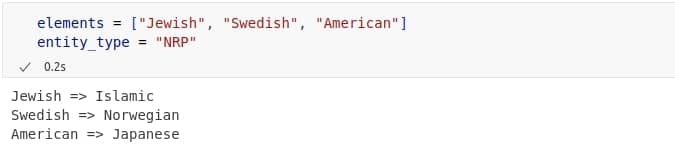
In the contextual replacement approach, entities are processed individually, relying on the information embedded within them, such as their type, format, or cultural and geographical context. In some cases, the entity's structure is enough to create a realistic replacement. For example, data elements like national ID numbers, passport codes, or IP addresses follow a predefined format, so they can be replaced with random but similar-looking values.
We used the Faker framework, which has built-in tools for generating fake but believable data. However, other entities, such as credit card numbers, IBANs, and phone numbers, need more careful handling to keep important details. For these, we implement custom transformers: the generated credit card matches the original issuer and passes checksum validation; IBAN codes follow the correct country format and are kept valid; phone numbers preserve their structure by replacing only the last few digits.
Conclusions
As AI becomes more integrated into our lives and business processes, data anonymization tools create a bridge between privacy requirements and technological advancement.
Our data anonymization tool tries to balance data privacy with AI utility. It replaces sensitive information with contextually suitable alternatives created locally, without relying on external services or cloud-based models. This way, users can fully leverage AI tools without exposing confidential data.
There’s still room for improvement. Our team plans to improve the handling of gender consistency during person name synthesis, improve entity recognition on noisy or informal input, support cross-entity conditions where values are dependent on one another, and develop specialized modes for medical texts and patent or IP-related documents where domain-specific patterns and sensitivities need special attention.


Related Insights









The breadth of knowledge and understanding that ELEKS has within its walls allows us to leverage that expertise to make superior deliverables for our customers. When you work with ELEKS, you are working with the top 1% of the aptitude and engineering excellence of the whole country.

Right from the start, we really liked ELEKS’ commitment and engagement. They came to us with their best people to try to understand our context, our business idea, and developed the first prototype with us. They were very professional and very customer oriented. I think, without ELEKS it probably would not have been possible to have such a successful product in such a short period of time.

ELEKS has been involved in the development of a number of our consumer-facing websites and mobile applications that allow our customers to easily track their shipments, get the information they need as well as stay in touch with us. We’ve appreciated the level of ELEKS’ expertise, responsiveness and attention to details.
