The online advertising industry is bigger than you think
The past decade has seen a huge growth in online advertising. It is an enormous industry with brands expected to pour over 30 billion of dollars in 2014. Online advertising provides companies with instant feedback and publishers with more knowledge about their users. Advertisers are very interested in precisely targeted ads. In particular, they want to spend the smallest amount of money and get the maximum increase in profit. This is resolved by applying targeted advertising.
The problem involves determining where, when, and to who to display particular advertisements on the Internet. Advertising systems deliver ads based on demographic, contextual, or behavioral attributes. Sponsored search is one example. It is the most profitable business model on the web and accounts for the huge amount of income for the top search engines Google, Yahoo, and Bing. It generates at least 25 billion dollars per year.
There are a couple of usable methods to do targeted advertising:
- Demographic Targeting – this approach defines the targeted audience by gender, age, income, location, etc. It is an old and efficient approach because it is easy to project behavior for products categories. Demographic targeting is popular since it’s easy to understand and implement. It provides advertiser transparence and control over the audience selected for targeting.
- Property Targeting – is a simple and popular targeting mechanism. The advertiser specifies set of pages where the ad should be shown. For example the company who sells tracks could show advertisement on website about vehicles.
- Behavioral Targeting – provides an approach to serve ads to users leveraging the past behavior of the user (searches, site visits, purchases). The most valuable resource for behavioral targeting is network traffic of particular user. The more such data you have, the better targeting result you will achieve. Thus, even local ISP companies can provide more accurate ads for consumer than Google or Yahoo.
Real-time bidding exchanges – de facto standard for targeted advertising
The online advertising industry has grown significantly during the past few years, with extensive usage of real-time bidding exchanges (RTB). This auction website allows advertisers to bid on the opportunity to place online display ads in real-time. Advertisers are integrated with an exchange system via API and collect a variety of data to decide whether or not to bid and at what price. This has created a simple and efficient method for companies to target advertisements to particular users.
As the industry standard, showing the display ad to the consumer is called “impression”. The auctions run in real-time and instantly trigger when a user navigates to the web page and take place during the time the page is completely loaded in the user’s browser. During the auction, information about the location of the potential advertisement, along with user information, is passed to bidders in the form of bid requests. This data is often appended with information previously collected by advertisers about the user.
When an auction starts, a potential advertiser makes the decision if it wants to bid on this impression, at which price, and what advertisement to show in case it wins the auction. There are billions of such real-time transactions each day, and advertisers require large-scale solutions to handle such auctions in milliseconds.
Such complicated ecosystems are a perfect opportunity for applying machine learning services, which play a key role in the ad bidding optimization process, increasing the targeting accuracy and reaching the ultimate goal from marketer’s perspective “Address the right browsers with the right message at the right moment and preferably at the right price”.
Improving ads relevance by applying Machine Learning techniques
The main task of a machine learning system is to identify prospective customers – online users who have a higher propensity to purchase a specific product in the near future after being displayed in the advertisement. The ultimate goal is to build a system that will learn predictive models for each ad targeting automatically. One of the challenges of building such systems is that different ad campaigns could have different performance measures.
However, each of these criteria may be approximately represented as some ranking of potential purchases in terms of purchase propensity. A primary source of input features for behavioral targeting is user browser history, recorded as a set of web pages visited in the past. The target labels could be individual for each campaign and based on actual purchases of the specific product. From a high level, this looks like an example of a straightforward predictive modeling problem. But if we take a closer look, it appears that it is impossible to obtain the necessary amount of training data directly for this problem.
First, the probability of purchase in the next 7 days after seeing the ads is very low and is in the range from 0.0000001 to 0.001, depending on the advertisement campaign. Second, the input feature vector includes more than one million features, even in the simplest case (considering the user browsing history is encoded as a set of hashed URLs). These dataset attributes involve difficulties in the training process, however, there are efficient approaches which are designed to predict the consumer purchase propensity in such difficult circumstances.
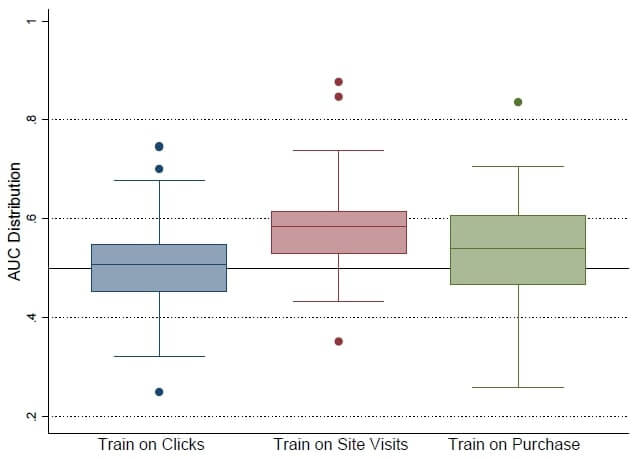
Site visits as better purchase predictors than click-through rate (CTR)
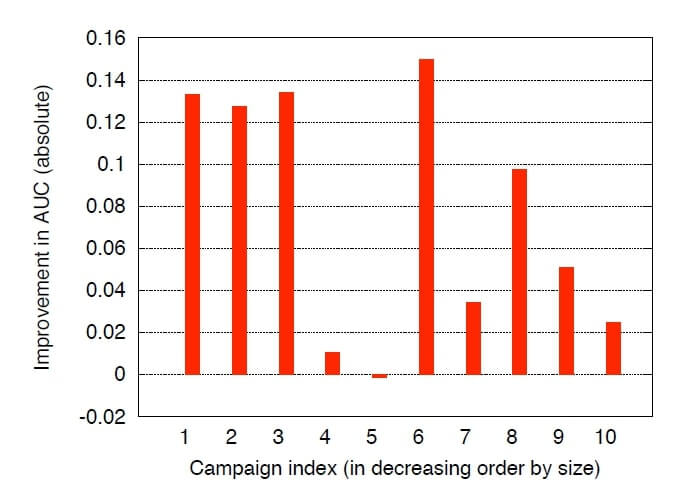
We know that the probability of purchasing after seeing the advertisement is a rare event. This causes model training with highly imbalanced class distribution (skewed classes). The simplest and most widely used approach is to introduce proxy-trained models. Currently, the most common proxy is clicking on an advertisement. The efficiency of campaigns is often evaluated based on “click-through rate” (CTR). As a result, they are optimized toward increased CTR.
In this approach, clicks on advertisements are treated as positive samples. Hence instead of conversions, the model is trained using clicks, but the test set is still labeled by conversions. In a recent study [1], this approach was tested against 10 different ad campaigns. The result implies that targeting based on clicks does not necessarily mean maximizing conversions.