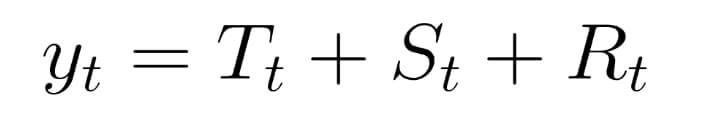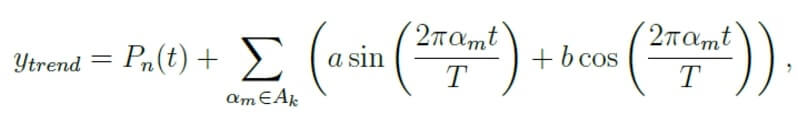Today, businesses need to be able to predict demand and trends to stay in line with any sudden market changes and economic swings. This is exactly where forecasting tools powered by Data Science come into play, enabling organizations to successfully deal with strategic and capacity planning. Smart forecasting techniques can be used to reduce any possible risks and assist in making well-informed decisions.
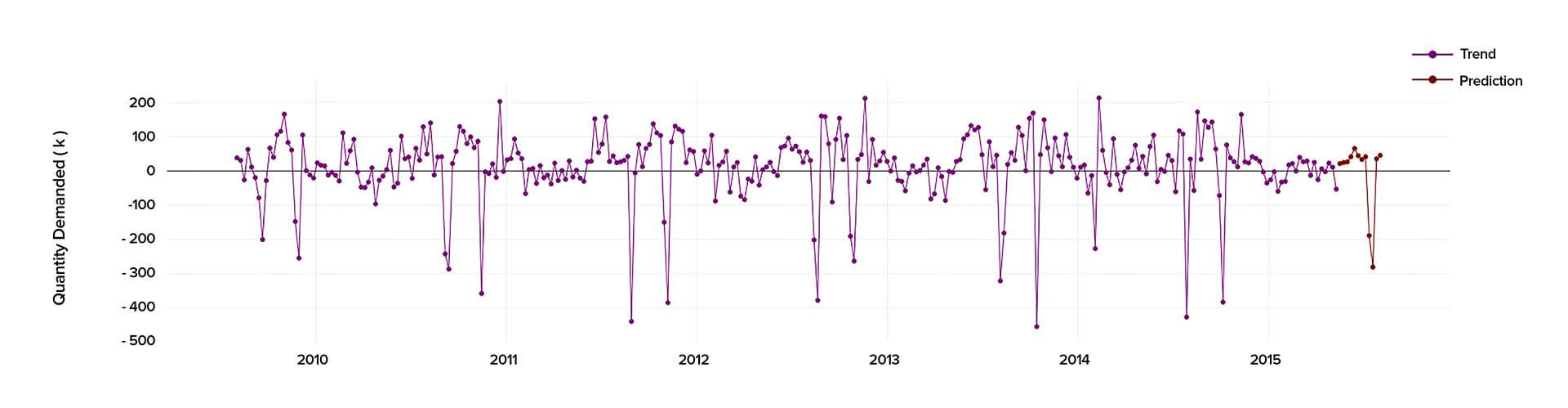
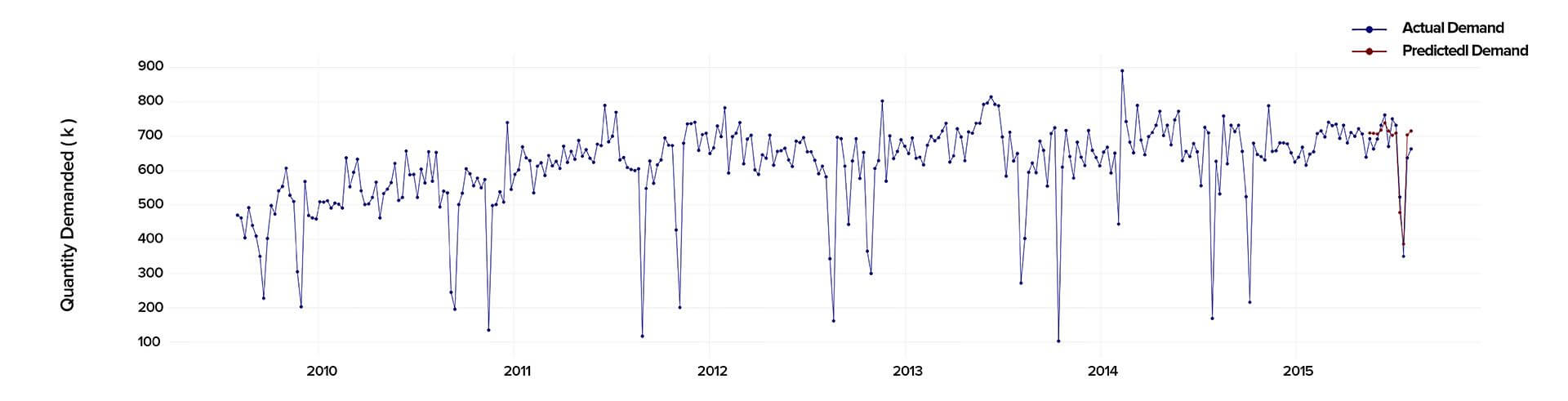
One of our customers, an enterprise from the Middle East, needed to predict their market demand for the upcoming twelve weeks. They required a market forecast to help them set their short-term objectives, such as production strategy, as well as assist in capacity planning and price control. So, we advised them to use our data science services to create a custom time series model capable of tackling the challenge. In this article, we will cover the modeling process as well as the pitfalls we had to overcome along the way.
There is a number of approaches to building time series prediction ….and neither fit us
With the emergence of the powerful forecasting methods based on Machine Learning, future predictions have become more accurate. In general, forecasting techniques can be grouped into two categories: qualitative and quantitative. Qualitative forecasts are applied when there is no data available and prediction is based only on expert judgement. Quantitative forecasts are based on time series modeling. This kind of models uses historical data and is especially efficient in forecasting some events that occur over periods of time: for example prices, sales figures, volume of production etc.
The existing models for time series prediction include the ARIMA models that are mainly used to model time series data without directly handling seasonality; VAR models, Holt-Winters seasonal methods, TAR models and other. Unfortunately, these algorithms may fail to deliver the required level of the prediction accuracy, as they can involve raw data that might be incomplete, inconsistent or contain some errors. As quality decisions are based only on quality data, it is crucial to perform preprocessing to prepare entry information for further processing.
Why combining models is an answer
It is clear that one particular forecasting technique cannot work in every situation. Each of the methods has its specific use case and can be applied with regard to many factors (the period over which the historical data is available, the time period that has to be observed, the size of the budget, the preferred level of accuracy) and the output required. So, we faced the question: which method/methods to use to obtain the desired result? As different approaches had their unique strengths and weaknesses, we decided to combine a number of methods and make them work together. In this way, we could build a time series model capable of providing trustworthy predictions to ensure data reliability and time/cost saving. And this is how we did it.
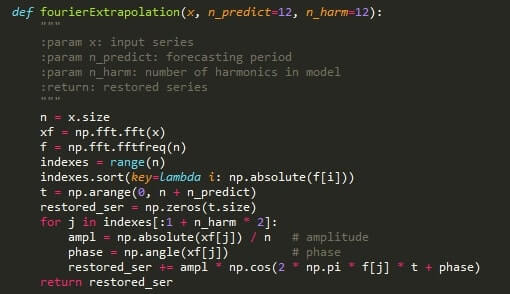
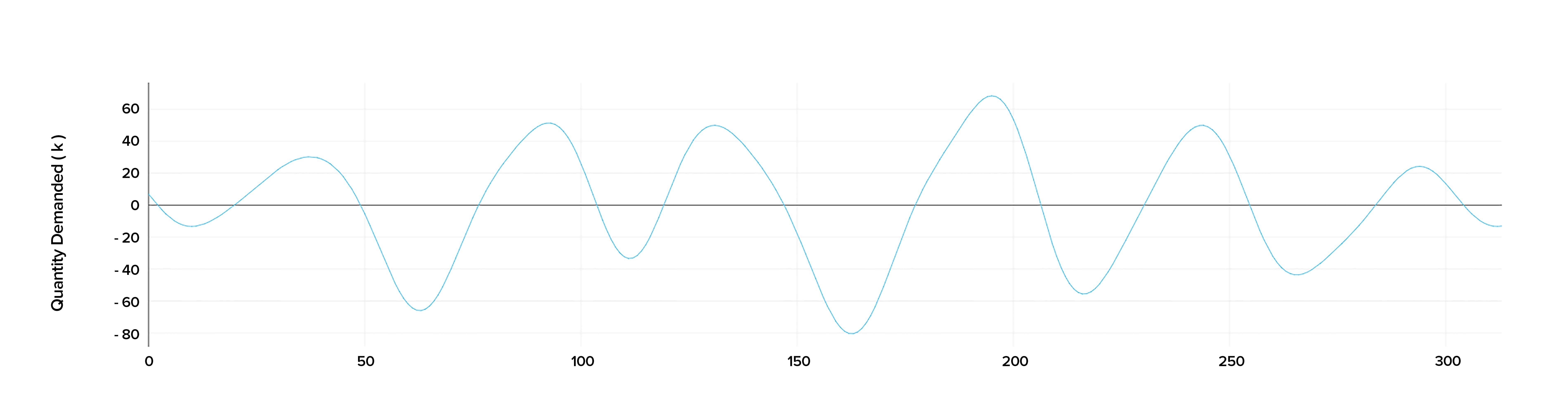
The modeling process; let's dive into the details
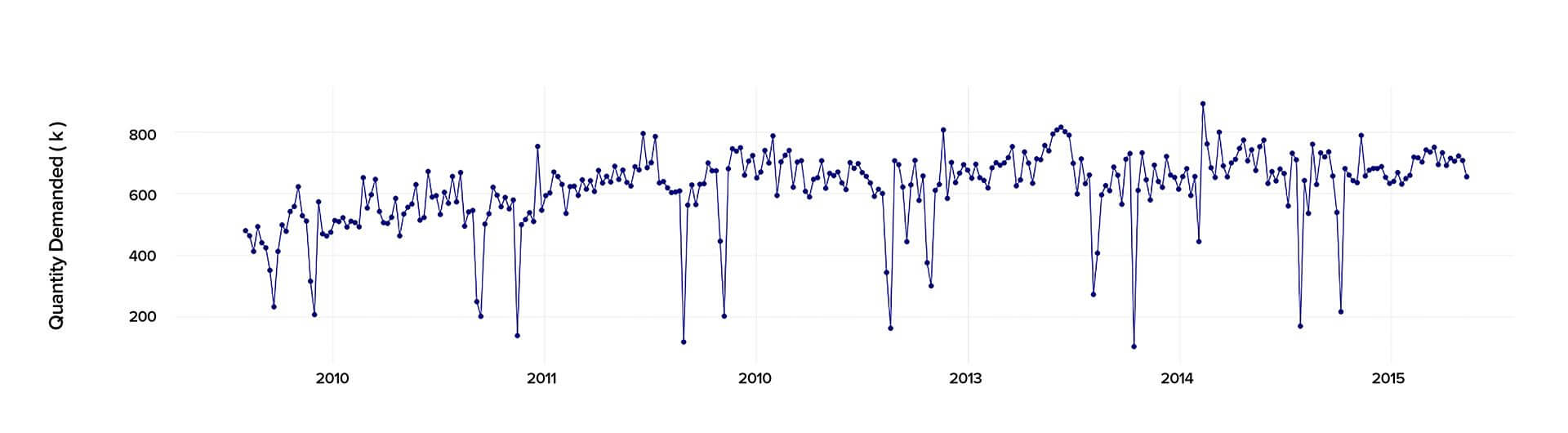
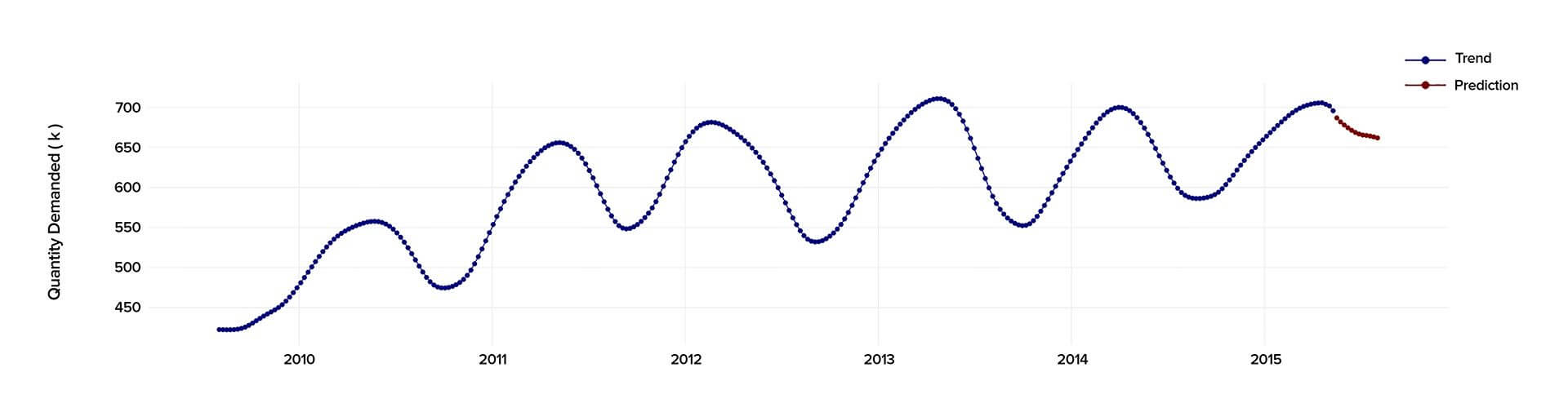
The demand data depends on various factors that can influence the result of the forecast, such as the price and types of goods, geographical location, the country’s economics, manufacturing technology, etc. As we wanted our time series model to provide the customer with high-accuracy predictions, we used the interpolation method for missing values to ensure that the input is reliable.
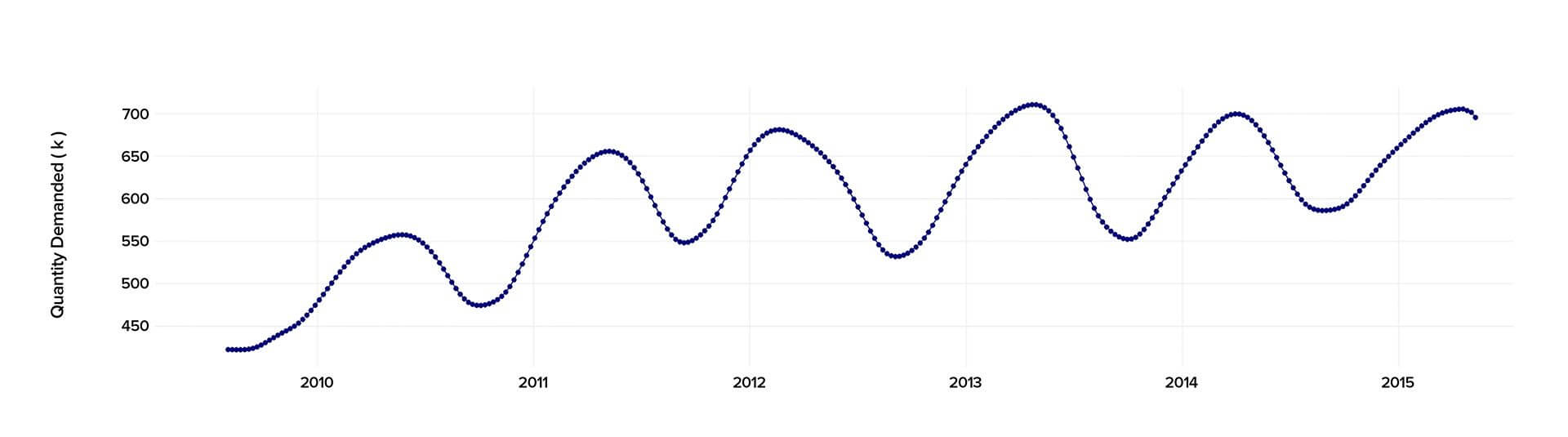
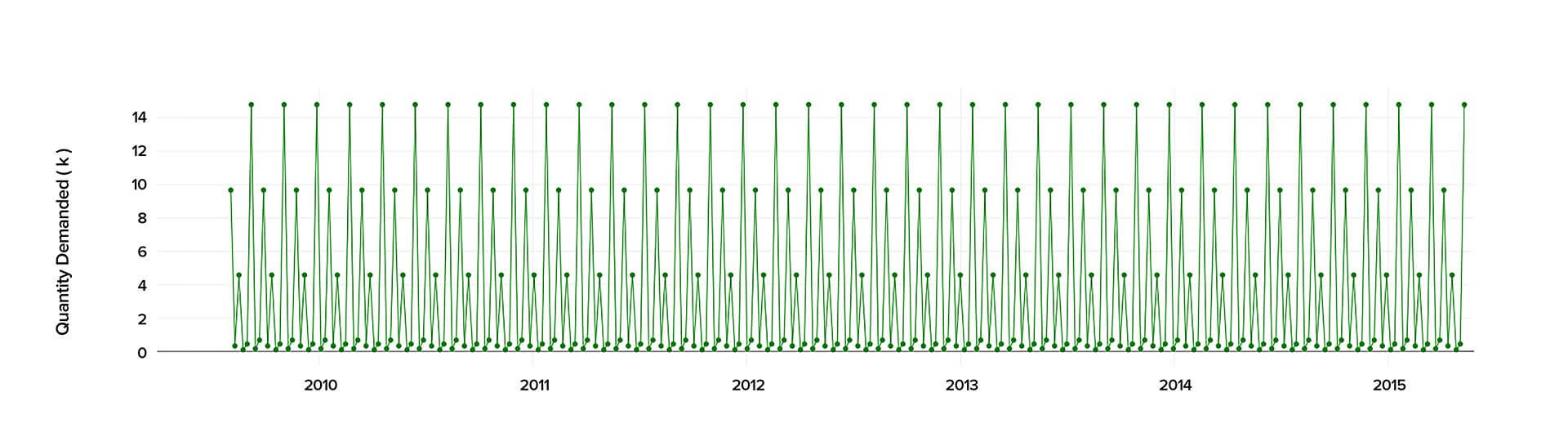
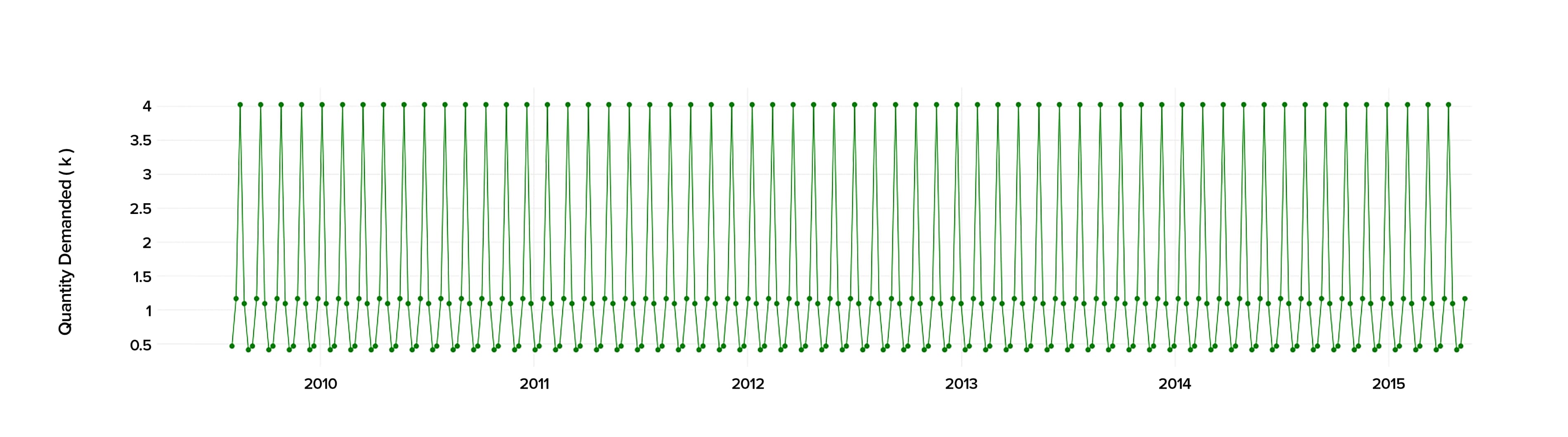
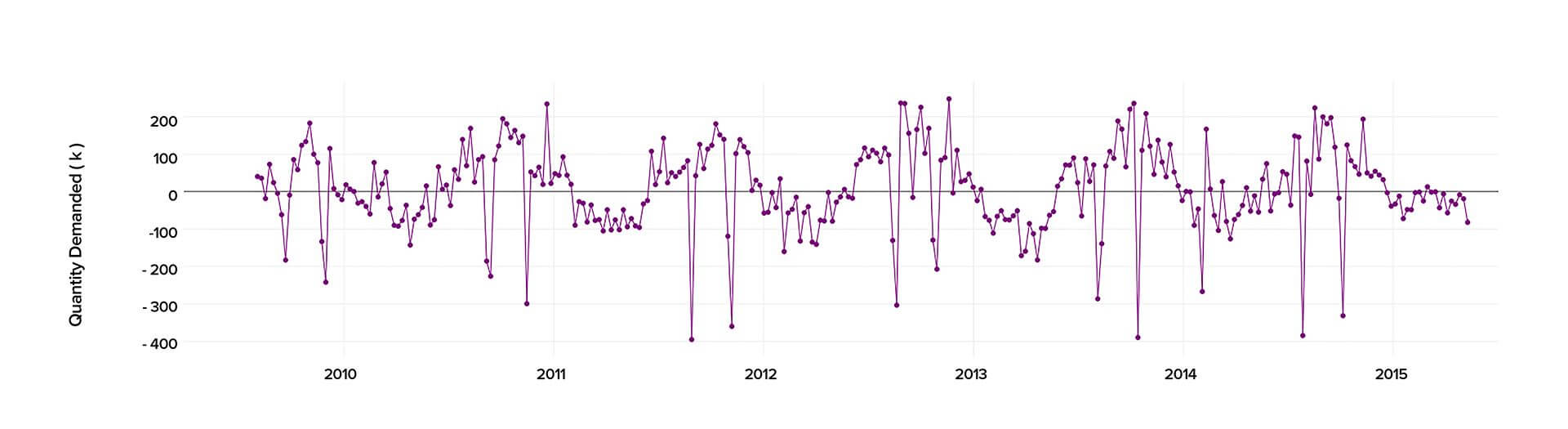
When conducting the time series analysis in Python 2.7., we analyzed the past data starting from 2010 to 2015 to calculate precisely the demand and predict its behavior in the future.