Evaluating unsupervised learning models
As unsupervised learning does not have predefined labels, the evaluation relies on specialised metrics and qualitative methods like visual inspection.
Elbow rule
The elbow rule is a method used to find the best number of clusters in unsupervised learning. It involves plotting the variance against the number of clusters and looking for a point where the decrease in variance slows down. This point is considered the optimal number of clusters.
Silhouette score
It defines how close an object (based on its features) is to its own cluster compared to other clusters, using a specific metric. The silhouette score ranges from -1 to 1, with higher values indicating well-separated clusters and correctly assigned data points. A silhouette score near 1 signifies clear cluster boundaries; scores close to 0 suggest overlapping clusters.
Calinski-Harabasz index
Also known as the Variance Ratio Criterion, it compares the dispersion between clusters to the dispersion of points within clusters. The higher the Calinski-Harabasz index, the better the clustering quality.
Davies-Bouldin index
This metric assesses clustering quality by evaluating the average similarity ratio between each cluster and its most similar cluster. A lower Davies-Bouldin index value signifies better clustering.
Visual inspection
Since there are no labels, data scientists use methods like PCA or t-SNE to reduce complex data into 2D or 3D plots. These plots help to see how the data points group together and whether the clusters are clear and separate. This method gives a clearer understanding of the data that might not be obvious from just numbers.
| Aspect |
Supervised Learning |
Unsupervised Learning |
| Data type |
Uses labelled data, where each input has a corresponding output label. |
Uses unlabelled data, where no explicit output labels are provided. |
| Supervision |
Involves external supervision, where the algorithm learns from the labelled data. |
No advanced supervision or labels; the model identifies patterns from the input data without labels. The only supervision is during validation. |
| Objective |
Aims to learn a mapping from inputs to outputs in order to accurately estimate future outputs. |
Aims to discover underlying patterns, groupings, or structures in the data. |
| Use case |
Used for tasks like classification (categorising data) and regression (predicting continuous values). |
Used for tasks like clustering (grouping similar data), dimensionality reduction (simplifying data), or data restoration/representation (autoencoders). |
| Learning process |
The algorithm learns from the relationships between the input data and known outputs. |
The unsupervised algorithm explores the input data and tries to find patterns or groupings based on the similarities. |
Data preparation
- Data cleaning: Handle missing values by imputing or removing them, remove duplicates, and fix errors in the data. (Note: In some cases, data cleaning is considered part of data preprocessing.)
- Preprocessing: Scale numerical features, encode categorical variables, and prepare the data for the model.
- Data splitting: The data is divided into training, validation, and test sets to train, optimise, and evaluate the model.
Feature engineering
- Feature selection: This step identifies and retains the most relevant features that significantly contribute to the model’s predictive capabilities.
- Feature transformation: Features are transformed to enhance the relationship between the input data and the target variable, thereby improving model performance.
- Feature creation: New, predictive features are derived from existing data to provide deeper insights and improve the model’s accuracy.
Model training
- Training: During this phase, the model learns the patterns and relationships between input features and the corresponding target labels.
- Optimisation: The model’s parameters are fine-tuned using optimisation algorithms to maximise performance and minimise error.
- Cross-validation: It is used to evaluate how well supervised learning models perform based on unseen data. It is beneficial when there is a lack of data or when you want to reduce the possibility of overfitting to a particular training set. It is used in 98% of cases as part of the ML estimator validation.
Model selection
- Performance metrics: The model’s effectiveness is evaluated using metrics such as accuracy, precision, recall, or mean squared error, depending on whether the task is classification or regression.
- Model comparison: A variety of models—such as decision trees, support vector machines (SVMs), and neural networks—are tested to identify the best-performing model for the task at hand.
- Hyperparameter tuning: The model’s hyperparameters (e.g., learning rate, regularisation) are adjusted to optimise performance.
Model deployment
- Integration: Once trained and selected, the model is deployed in a production environment, where it can make real-time or batch predictions based on incoming data.
- Monitoring: To check the model's performance and if it remains consistent, accurate, and reliable as it processes new data.
Model maintenance
- Updating: Over time, the model may require retraining with new data to maintain its accuracy and relevance.
- Refinement: If issues such as concept drift (when data patterns change over time) arise, the model may need to be refined or restructured to address these challenges.
- Retraining: As new data becomes available, the model is retrained to adapt to evolving trends and ensure its continued predictive power.
Dive deeper into the details—read our article on the ML model lifecycle next.
- Image classification and object detection. A model is trained to recognise and classify images into set categories, like identifying animals in photos. In object detection, supervised learning is used to detect and locate objects within images, such as recognising pedestrians or vehicles in autonomous driving.
- Customer churn prediction and recommendation tasks. In customer churn prediction, it predicts whether a customer is likely to leave a service based on historical data. Supervised learning is also crucial for building recommendation systems that suggest products or services to customers based on past behaviours and preferences.
- Predictive modelling and regression analysis. In predictive modelling, supervised learning algorithms are trained to predict future outcomes on historical data. It can predict sales figures, stock prices, or customer behaviour. In regression analysis, supervised learning models are used to understand relationships between variables and predict continuous outcomes, such as predicting house prices based on features like size and location.
- Image segmentation and anomaly detection. Unsupervised learning can be used for anomaly detection, such as finding unusual patterns or outliers in data. For instance, in fraud detection, unsupervised learning can spot unusual financial transactions that might indicate fraud. In network security, it helps identify abnormal activities, such as potential hacking attempts.
- Customer segmentation and clustering. It allows businesses to identify distinct customer groups based on purchasing behaviour, demographics, or other features. This helps in targeted marketing and personalised customer experiences. For example, retailers use unsupervised learning to group customers with similar shopping habits, enabling them to tailor promotions effectively.
For more, read our blog post: Harnessing the Power of Behavioural Data Analytics in the Insurance Industry
- Exploratory data analysis and dimensionality reduction. In exploratory data analysis (EDA), unsupervised learning tries to identify unusual patterns and structures in data. Additionally, dimensionality reduction techniques, such as PCA, help reduce the complexity of high-dimensional data while retaining valuable information. This is especially useful for visualising data or improving the performance of other machine learning models.
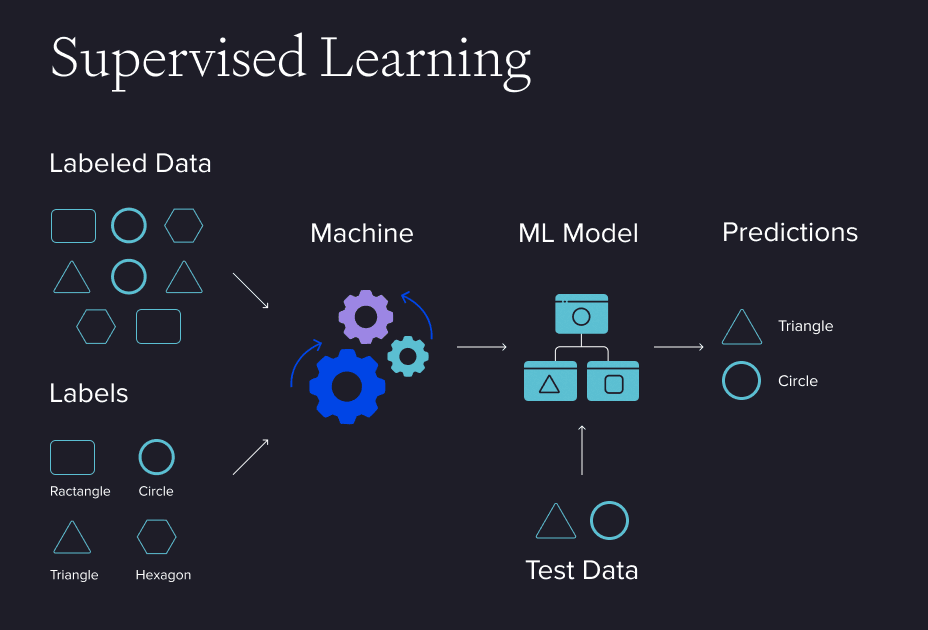
Supervised learning
- High accuracy: Supervised learning models make highly accurate predictions on new. For example, image classification models can often achieve over 90% accuracy in identifying objects in images.
- Less risk of overfitting: The model is less likely to simply memorise the training data. Instead, it learns patterns that can apply to new data, making it better at handling different situations.
- Wide variety of algorithms: Supervised learning offers a wide range of well-established algorithms, such as linear regression, random forests, support vector machines (SVM), and neural networks, which provide flexibility and effectiveness for various tasks.
- Requires a large amount of labelled data: One significant drawback is that obtaining labelled data can be expensive and time-consuming. In many cases, gathering thousands of labelled examples may not be practical.
- Not suitable for unstructured data: Supervised models typically perform poorly on unstructured data, such as text, audio, and video, which are more challenging and costly to label.
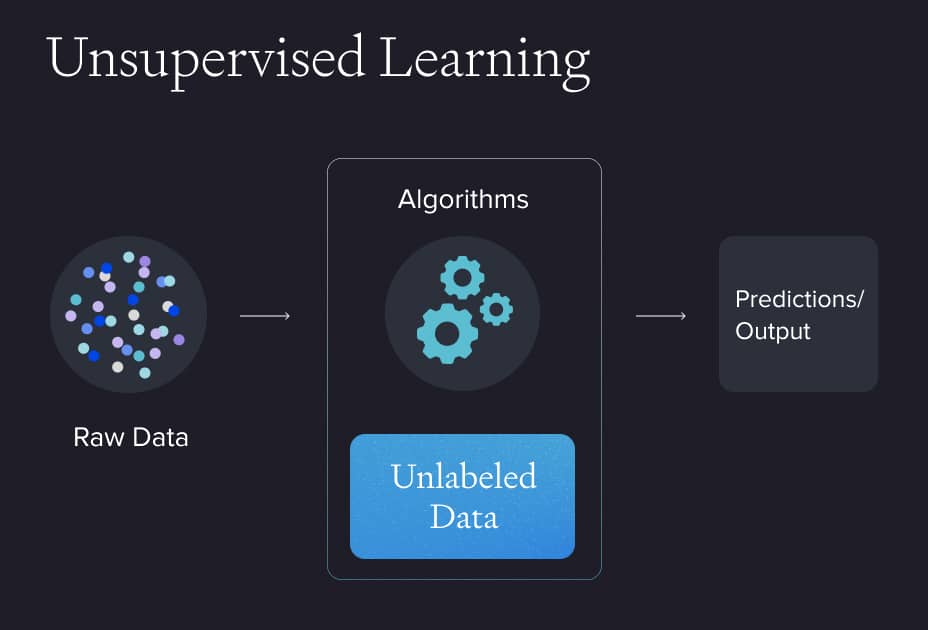
Unsupervised learning
- Can work with unlabelled data: Unsupervised learning algorithms are particularly valuable because they do not require labelled data to find patterns or structures within it.
- Uncovers hidden insights: Techniques like clustering and association rule mining are excellent for discovering interesting groupings and patterns in large, unlabelled datasets.
- Subjective results: The outcomes are subjective and depend on how the human interprets them and on human intervention.
- Prone to overfitting: Without the guidance of labelled data, unsupervised models may fit too closely to spurious or irrelevant patterns in the data.
Supervised learning is ideal for making precise predictions but relies heavily on labelled data, which can be difficult and expensive. On the other hand, unsupervised learning is well-suited for discovering patterns in unlabelled data but may lack clear accuracy metrics and is more prone to subjective interpretation.
The choice between these methods depends on the specific application and data availability.
Medical diagnosis in healthcare
Supervised learning is used to develop predictive models that help doctors diagnose diseases based on medical images or patient data. For example, algorithms are trained on labelled datasets of X-rays or MRIs. Each image is tagged with a diagnosis (e.g., cancerous or non-cancerous).
In the healthcare industry, this approach improves diagnostic accuracy, reduces human error, and speeds up diagnosis and treatment. By integrating supervised learning into healthcare software, organisations can harness advanced predictive models to support more efficient medical decision-making.
Credit scoring in finance
In the fintech industry, banks and financial institutions apply supervised learning to predict whether a person will likely repay a loan. Historical data, such as income, credit history, and employment status, labelled with default or on-time repayment outcomes, is used to train these models. Once trained, the models predict the likelihood of default for new applicants. This approach, powered by fintech solutions, helps assess creditworthiness, mitigate risk for lenders, and streamline loan approval processes.
Customer segmentation in retail
Retailers analyse customer data and purchasing behaviour (e.g., frequency of purchases, types of products bought) without predefined labels. Clustering algorithms like k-means can group customers with similar buying behaviours into distinct segments, which can be targeted with personalised marketing strategies.
This approach helps businesses that use retail software understand customer preferences, create tailored marketing campaigns, and optimise inventory management based on different customer needs.
Anomaly detection in cybersecurity
Unsupervised learning is used to detect unusual activity in networks that may indicate a cybersecurity threat, such as a potential data breach or a new type of malware. Without prior knowledge of specific attacks, anomaly detection algorithms analyse network traffic or user behaviour to identify patterns that deviate from the norm, signalling a possible threat.
With the help of cyber security services, companies can apply unsupervised learning techniques to identify novel or unknown attacks, strengthening their security infrastructure and proactively detecting threats before they cause significant damage.
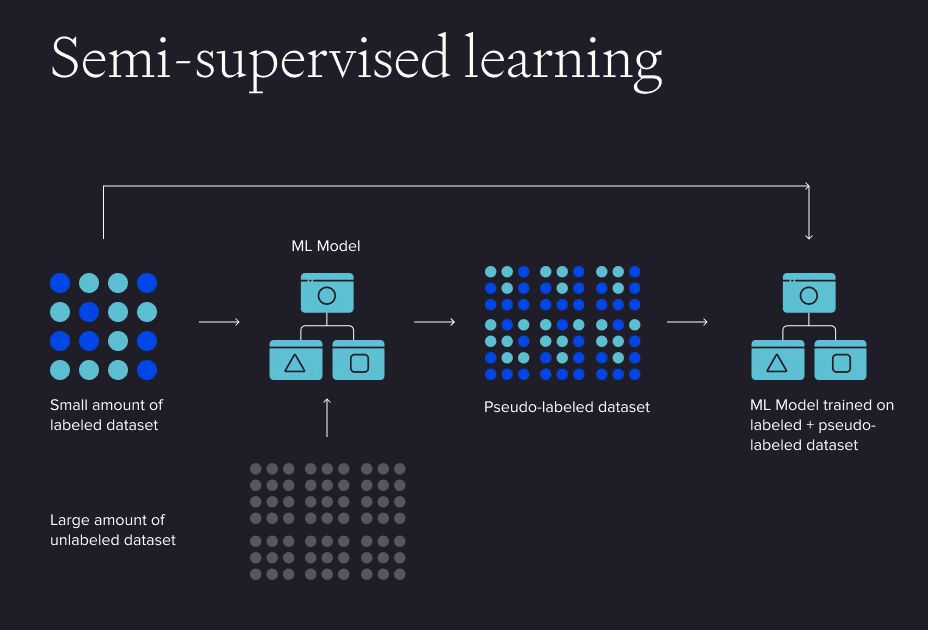
Discussing supervised and unsupervised models, it is also worth mentioning semi-supervised learning as it combines the best aspects of both. Semi-supervised learning (Figure 3) is a type of machine learning that combines a small amount of labelled data with a large amount of unlabelled data to train models. This approach merges elements of supervised learning, which utilises labelled training data, and unsupervised learning, which relies on unlabelled training data. In essence, it incorporates both supervised and unsupervised learning techniques.